
Topics in machine learning#
KEYWORDS: autograd
Choice of activation functions in neural networks#
The activation function in a neural network provides the nonlinearity in the model. We previously learned that one interpretation of the activation function is that it is a basis function that you can expand the data in to find a functional representation that fits the data.
Today we explore the impact of the activation function on the fitting, and extrapolation of neural networks. The following code is for setting up a neural network, and initializing the parameters with random numbers.
layer_sizes = [1, 3, 1]
list(zip(layer_sizes[:-1], layer_sizes[1:]))
[(1, 3), (3, 1)]
import autograd.numpy as np
import autograd.numpy.random as npr
def nn(params, inputs, activation=np.tanh):
"""a neural network.
params is a list of (weights, bias) for each layer.
inputs goes into the nn. Each row corresponds to one output label.
activation is the nonlinear activation function.
"""
for W, b in params[:-1]:
outputs = np.dot(inputs, W) + b
inputs = activation(outputs)
# no activation on the last layer
W, b = params[-1]
return np.dot(inputs, W) + b
def init_random_params(scale, layer_sizes, rs=npr.RandomState(0)):
"""Build a list of (weights, biases) tuples, one for each layer."""
return [
(
rs.randn(insize, outsize) * scale, # weight matrix
rs.randn(outsize) * scale,
) # bias vector
for insize, outsize in zip(layer_sizes[:-1], layer_sizes[1:])
]
init_random_params(0.1, (1, 3, 1))
[(array([[0.17640523, 0.04001572, 0.0978738 ]]),
array([ 0.22408932, 0.1867558 , -0.09772779])),
(array([[ 0.09500884],
[-0.01513572],
[-0.01032189]]),
array([0.04105985]))]
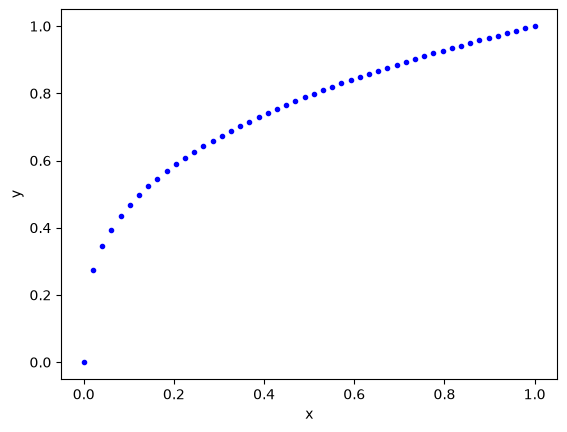
As before, we are going to consider this dataset so we can evaluate fitting and extrapolation.
# Some generated data
X = np.linspace(0, 1)
Y = X ** (1.0 / 3.0)
import matplotlib.pyplot as plt
plt.plot(X, Y, "b.")
plt.xlabel("x")
plt.ylabel("y");
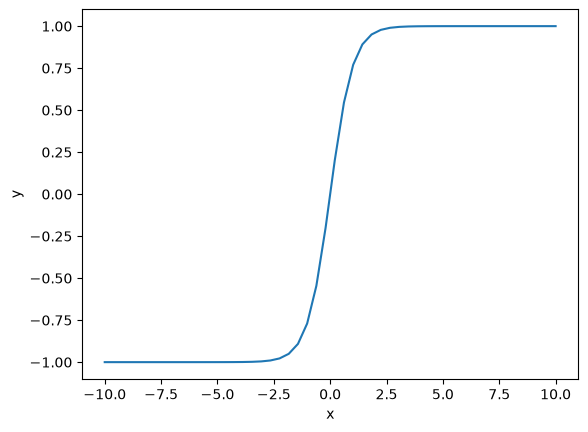
tanh#
First we review the case of tanh which is a classic activation function. The tanh function is “active” between about ± 2.5, and outside that window it saturates. That means the derivative of this function becomes close to zero outside that window. So if you have large values of inputs, you should scale them to avoid this issue.
xt = np.linspace(-10, 10)
plt.plot(xt, np.tanh(xt))
plt.xlabel("x")
plt.ylabel("y");
def objective1(params, step=None):
pred = nn(params, np.array([X]).T)
err = np.array([Y]).T - pred
return np.mean(err**2)
from autograd.misc.optimizers import adam
from autograd import grad
params1 = init_random_params(0.1, layer_sizes=[1, 3, 1])
N = 50
MAX_EPOCHS = 500
for i in range(MAX_EPOCHS):
params1 = adam(grad(objective1), params1, step_size=0.01, num_iters=N)
if i % 100 == 0: # print every 100th step
print(f"Step {i}: {objective1(params1)}")
if objective1(params1, _) < 2e-5:
print("Tolerance reached, stopping")
break
Step 0: 0.02031579054497994
Step 100: 9.470108542516542e-05
Tolerance reached, stopping
params1
[(array([[ 0.85815232, 3.00081722, 33.46094838]]),
array([-0.44095266, 0.20622903, 0.57208747])),
(array([[0.4381347 ],
[0.3981554 ],
[0.66964933]]),
array([-0.24135422]))]
Now we can examine the fit and extrapolation.
X2 = np.linspace(-2, 10)
Y2 = X2 ** (1 / 3)
Z2 = nn(params1, X2.reshape([-1, 1]))
plt.plot(X2, Y2, "b.", label="analytical")
plt.plot(X2, Z2, label="NN")
plt.fill_between(X2 < 1, 0, 1.4, facecolor="gray", alpha=0.5)
plt.xlabel("x")
plt.ylabel("y");
/tmp/ipykernel_3203/1979846641.py:2: RuntimeWarning: invalid value encountered in power
Y2 = X2 ** (1 / 3)
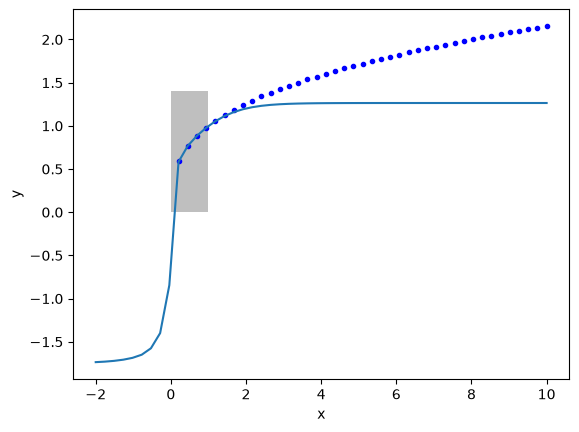
For large enough \(x\), all of the tanh functions saturate at \(y=1\). So, the neural network also saturates at a constant value for large \(x\).
exercise Can you work out from the NN math what the saturated values should be?
relu#
A common activation function in deep learning is the Relu:
def relu(x):
return x * (x > 0)
plt.plot(X2, relu(X2));
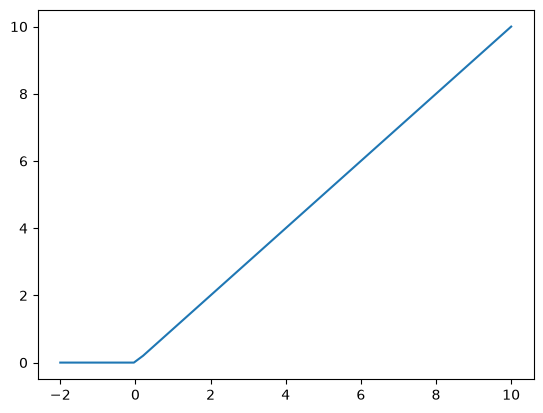
This is popular because if is very fast to compute, and the derivatives are constant. For positive \(x\) there is no saturation. For negative \(x\), however, the neuron is “dead”.
def objective2(par, step=None):
pred = nn(par, np.array([X]).T, activation=relu)
err = np.array([Y]).T - pred
return np.mean(err**2)
from autograd.misc.optimizers import adam
from autograd import grad
params2 = init_random_params(0.01, layer_sizes=[1, 3, 1])
N = 50
MAX_EPOCHS = 500
for i in range(MAX_EPOCHS):
params2 = adam(grad(objective2), params2, step_size=0.01, num_iters=N)
if i % 100 == 0: # print every 100th step
print(f"Step {i}: {objective2(params2)}")
if objective2(params2, _) < 2e-5:
print("Tolerance reached, stopping")
break
Step 0: 0.022935107138404756
Step 100: 0.005829843039978749
Step 200: 0.005829606810484628
Step 300: 0.0058293834707628354
Step 400: 0.005829150369017916
X2 = np.linspace(0.0, 1)
Y2 = X2 ** (1 / 3)
Z2 = nn(params2, X2.reshape([-1, 1]), activation=relu)
plt.plot(X2, Y2, "b.", label="analytical")
plt.plot(X2, Z2, label="NN")
plt.xlabel("x")
plt.ylabel("y");
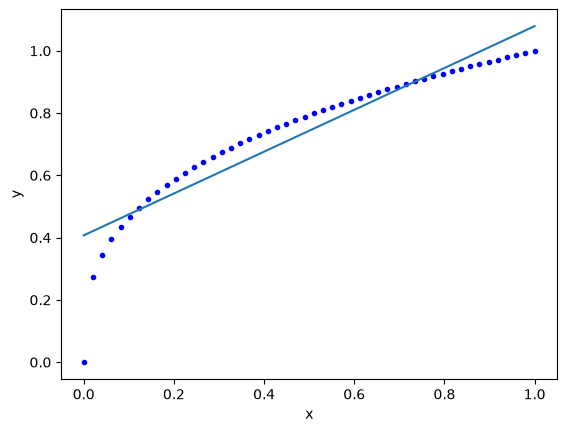
params2
[(array([[-0.0255299 , 1.1907681 , 0.00864436]]),
array([-0.00742165, 0.01023201, -0.01454366])),
(array([[4.57585173e-04],
[5.64269160e-01],
[1.53277921e-02]]),
array([0.40150588]))]
Notes:
The fit is not very good.
we have piecewise linear fits here.
There are negative weights, which means there are some “dead neurons”. Maybe other initial guesses might improve this.
Let’s look at the extrapolating behavior.
X2 = np.linspace(0, 1)
Y2 = X2 ** (1 / 3)
xf = np.linspace(-2, 2)
Z2 = nn(params2, xf.reshape([-1, 1]), activation=relu)
plt.plot(X2, Y2, "b.", label="analytical")
plt.plot(xf, Z2, label="NN")
plt.fill_between(X2 < 1, 0, 1.4, facecolor="gray", alpha=0.5)
plt.xlabel("x")
plt.ylabel("y");
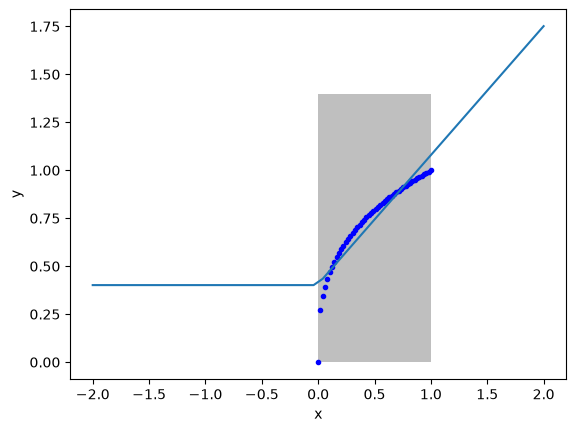
Notes this extrapolates linearly on the right, and is constant on the left. These are properties of the Relu.
Gaussian (radial basis function)#
Finally we consider the Gaussian activation function.
def rbf(x):
return np.exp(-(x**2))
x3 = np.linspace(-3, 3)
plt.plot(x3, rbf(x3));
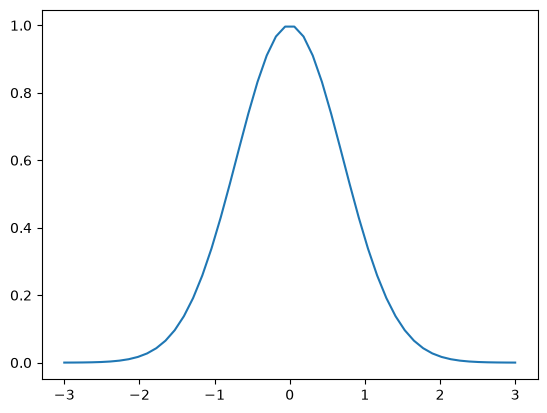
Now we fit the data.
def objective3(pars, step=None):
pred = nn(pars, np.array([X]).T, activation=rbf)
err = np.array([Y]).T - pred
return np.mean(err**2)
from autograd.misc.optimizers import adam
from autograd import grad
params3 = init_random_params(0.1, layer_sizes=[1, 3, 1])
N = 50
MAX_EPOCHS = 500
for i in range(MAX_EPOCHS):
params3 = adam(grad(objective3), params3, step_size=0.01, num_iters=N)
if i % 100 == 0: # print every 100th step
print(f"Step {i}: {objective3(params3)}")
if objective3(params3, _) < 2e-5:
print("Tolerance reached, stopping")
break
Step 0: 0.04118988111874795
Step 100: 0.0011480838738765103
Step 200: 0.0010860434402444863
Step 300: 0.0010205294778858549
Step 400: 0.0009187065515652205
X2 = np.linspace(0.0, 1)
Y2 = X2 ** (1 / 3)
Z2 = nn(params3, X2.reshape([-1, 1]), activation=rbf)
plt.plot(X2, Y2, "b.", label="analytical")
plt.plot(X2, Z2, label="NN")
plt.xlabel("x")
plt.ylabel("y");
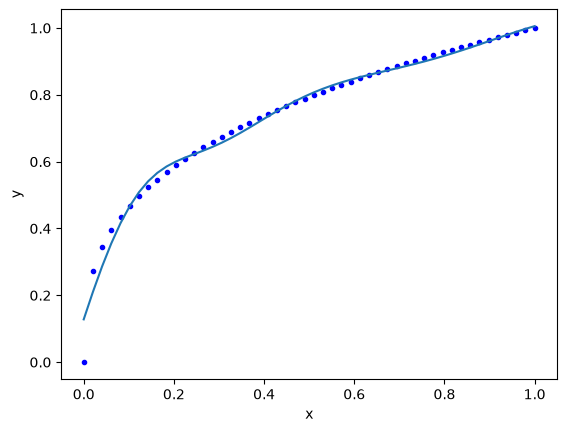
Note we have piecewise linear fits here.
X2 = np.linspace(-2.5, 5)
Y2 = X2 ** (1 / 3)
Z2 = nn(params3, X2.reshape([-1, 1]), activation=rbf)
plt.plot(X2, Y2, "b.", label="analytical")
plt.plot(X2, Z2, label="NN")
plt.fill_between(X2 < 1, 0, 1.4, facecolor="gray", alpha=0.5)
plt.xlabel("x")
plt.ylabel("y");
/tmp/ipykernel_3203/1811357780.py:2: RuntimeWarning: invalid value encountered in power
Y2 = X2 ** (1 / 3)
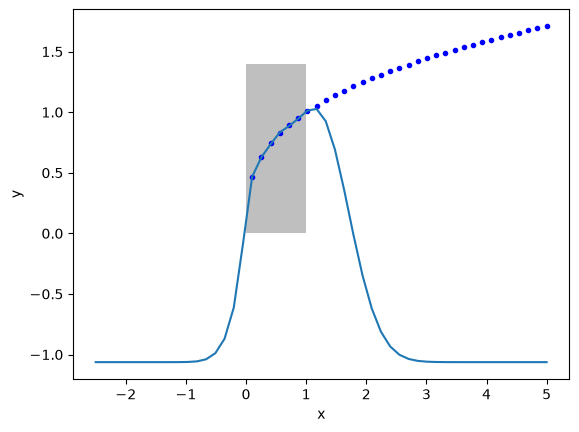
Notes this extrapolates to zero when you are far from the data. It fits reasonably in the region trained. “If your function is nonlinear enough, somewhere the nonlinearity matches your data.” (Z. Ulissi).
def objective33(pars, step=None):
pred = nn(pars, np.array([X]).T, activation=np.sin)
err = np.array([Y]).T - pred
return np.mean(err**2)
from autograd.misc.optimizers import adam
from autograd import grad
params33 = init_random_params(0.1, layer_sizes=[1, 3, 1])
N = 50
MAX_EPOCHS = 500
for i in range(MAX_EPOCHS):
params33 = adam(grad(objective33), params33, step_size=0.01, num_iters=N)
if i % 100 == 0: # print every 100th step
print(f"Step {i}: {objective33(params33)}")
if objective33(params33, _) < 2e-5:
print("Tolerance reached, stopping")
break
Step 0: 0.018983980286734897
Step 100: 0.001471571111187035
Step 200: 0.0014284835624584693
Step 300: 0.001363975102458357
Step 400: 0.000991705501622479
X2 = np.linspace(-15, 5)
Y2 = X2 ** (1 / 3)
Z2 = nn(params3, X2.reshape([-1, 1]), activation=np.sin)
plt.plot(X2, Y2, "b.", label="analytical")
plt.plot(X2, Z2, label="NN")
plt.fill_between(X2 < 1, 0, 1.4, facecolor="gray", alpha=0.5)
plt.xlabel("x")
plt.ylabel("y");
/tmp/ipykernel_3203/4141779018.py:2: RuntimeWarning: invalid value encountered in power
Y2 = X2 ** (1 / 3)
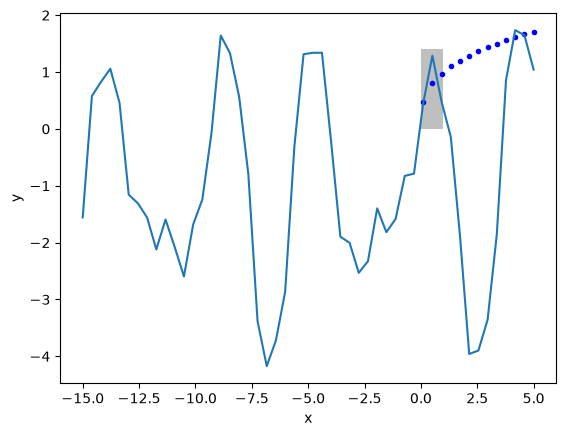
Exercise how many neurons do you need to get a better fit for sin as the activation function.
Summary#
We can think of single layer neural networks as partial expansions in the activation function space. That means the extrapolation behavior will be like the dominating feature of the activation functions, e.g. relu extrapolates like a line, tanh saturates at large x, and Gaussians effectively go to zero. Unexpected things can happen at the edges of the data, so at intermediate extrapolations you do not always know what will happen.
Train/test splits on data#
So far we have not considered how to split your data when fitting. This becomes important for a few reasons:
We need to be able to tell if we are overfitting. One way to do this is to compare fitting errors to prediction errors.
This means we need a way to split a dataset into a train set and a test set. Then, we can do training on the train set, and testing on the test set.
Let’s start by remembering what our dataset is.
X = np.linspace(0, 1)
Y2 = X ** (1 / 3)
X, Y2
(array([0. , 0.02040816, 0.04081633, 0.06122449, 0.08163265,
0.10204082, 0.12244898, 0.14285714, 0.16326531, 0.18367347,
0.20408163, 0.2244898 , 0.24489796, 0.26530612, 0.28571429,
0.30612245, 0.32653061, 0.34693878, 0.36734694, 0.3877551 ,
0.40816327, 0.42857143, 0.44897959, 0.46938776, 0.48979592,
0.51020408, 0.53061224, 0.55102041, 0.57142857, 0.59183673,
0.6122449 , 0.63265306, 0.65306122, 0.67346939, 0.69387755,
0.71428571, 0.73469388, 0.75510204, 0.7755102 , 0.79591837,
0.81632653, 0.83673469, 0.85714286, 0.87755102, 0.89795918,
0.91836735, 0.93877551, 0.95918367, 0.97959184, 1. ]),
array([0. , 0.27327588, 0.34430604, 0.39413203, 0.43379842,
0.46729519, 0.49657523, 0.52275796, 0.54655177, 0.56843674,
0.58875504, 0.60776012, 0.62564559, 0.64256306, 0.65863376,
0.67395628, 0.68861208, 0.70266925, 0.71618542, 0.72920982,
0.74178487, 0.75394744, 0.76572977, 0.77716026, 0.78826405,
0.79906353, 0.80957873, 0.81982765, 0.82982653, 0.83959009,
0.84913171, 0.85846357, 0.86759685, 0.87654178, 0.88530778,
0.89390354, 0.90233709, 0.91061587, 0.9187468 , 0.9267363 ,
0.93459037, 0.94231461, 0.94991425, 0.9573942 , 0.96475906,
0.97201316, 0.97916057, 0.98620513, 0.99315047, 1. ]))
The way to split this is that we use indexing. We start by making an array of integers.
ind = np.arange(len(X))
ind
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33,
34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49])
Next, we randomly shuffle the array of integers.
pind = np.random.permutation(ind)
pind
array([ 5, 31, 27, 14, 30, 44, 34, 11, 43, 12, 28, 16, 3, 18, 19, 7, 38,
42, 10, 36, 26, 21, 39, 29, 40, 46, 17, 15, 49, 47, 2, 33, 4, 6,
22, 37, 48, 13, 24, 1, 8, 45, 0, 9, 32, 41, 25, 35, 23, 20])
Next, we decide on the train/test split. A common choice is 80/20. We find the integer that is closest to 80% of the index array.
split = int(0.8 * len(pind))
split
40
train_ind = pind[:split]
test_ind = pind[split:]
print(len(train_ind), len(test_ind))
test_ind
40 10
array([ 8, 45, 0, 9, 32, 41, 25, 35, 23, 20])
We check that we have a reasonable choice here.
train_x = X[train_ind]
train_y = Y2[train_ind]
test_x = X[test_ind]
test_y = Y2[test_ind]
plt.plot(test_x, test_y, "ro")
plt.plot(train_x, train_y, "bo")
plt.legend(["test", "train"]);
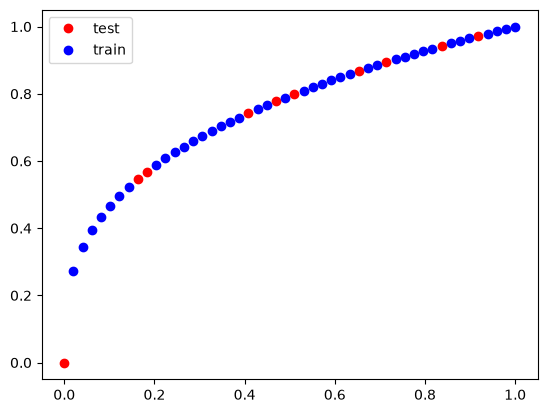
Now, we train on the train data.
def objective10(params, step=None):
pred = nn(params, np.array([train_x]).T)
err = np.array([train_y]).T - pred
return np.mean(err**2)
from autograd.misc.optimizers import adam
from autograd import grad
params10 = init_random_params(0.1, layer_sizes=[1, 3, 1])
N = 50
MAX_EPOCHS = 500
for i in range(MAX_EPOCHS):
params10 = adam(grad(objective10), params10, step_size=0.01, num_iters=N)
if i % 100 == 0: # print every 100th step
print(f"Step {i}: {objective10(params10)}")
if objective10(params10, _) < 2e-5:
print("Tolerance reached, stopping")
break
Step 0: 0.016212321284670407
Tolerance reached, stopping
As usual, we should check the fit on the train data. This is a little trickier than before, because the points are out of order.
Z2 = nn(params10, train_x.reshape([-1, 1]))
plt.plot(train_x, Z2, "bo", label="NN")
plt.plot(train_x, train_y, "r+", label="analytical")
plt.xlabel("x")
plt.ylabel("y")
plt.plot(test_x, nn(params10, test_x.reshape([-1, 1])), "go", label="NN")
plt.plot(test_x, test_y, "y*", label="analytical");
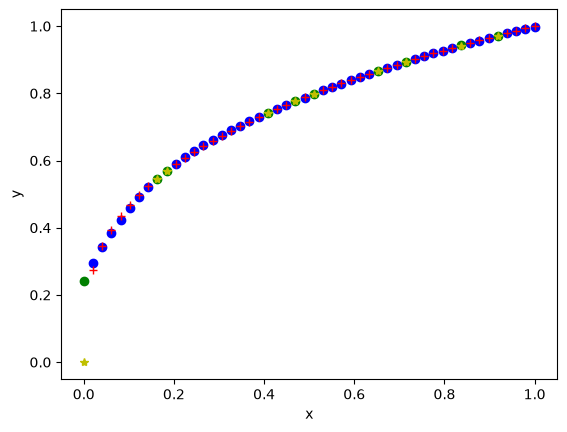
rmse_train = np.mean((train_y - nn(params10, train_x.reshape([-1, 1])) ** 2))
rmse_test = np.mean((test_y - nn(params10, test_x.reshape([-1, 1])) ** 2))
print(f"""RMSE train = {rmse_train:1.3f}
RMSE test = {rmse_test:1.3f}""")
RMSE train = 0.150
RMSE test = 0.126
Here, the test RMSE is a little higher than the train data. This suggests a possible overfitting, but not by much. This may also be due to extrapolation errors because the first two test points are technically outside the training data. For the train/test split to be meaningful, it is important that the two datasets have similar distributions of values.
Summary#
Today we reviewed the role of activation functions in neural networks, and observed that it doesn’t generally matter what you use (but the details always matter in individual cases). The mathematical form of these activation functions determines how they will extrapolate, which can be important depending on your application.
We then explored how to efficiently split a dataset into a train and test set so that overfitting can be evaluated. This becomes increasingly important for when you plan to explore many models (choices of hyperparameters), and then you split the data three ways (train, test and validate).