
Nonlinear regression#
KEYWORDS: scipy.optimize.minimize, scipy.optimize.curve_fit, pycse.nlinfit
Regression of data is a form of function minimization#
When we say regression, we really mean find some parameters of a model that best reproduces some known data. By “best reproduces” we mean the sum of all the errors between the values predicted by the model, and the real data is minimized.
Suppose we have the following data that shows how the energy of a material depends on the volume of the material.
import numpy as np
import matplotlib.pyplot as plt
volumes = np.array([13.71, 14.82, 16.0, 17.23, 18.52])
energies = np.array([-56.29, -56.41, -56.46, -56.463, -56.41])
plt.plot(volumes, energies, "bo")
plt.xlabel("V")
plt.ylabel("E");

In Materials Science we often want to fit an equation of state to this data. We will use this equation:
\(E = E_0 + \frac{B_0 V}{B_0'}\left(\frac{(V_0 / V)^{B_0'}}{B_0' - 1} + 1 \right) - \frac{V_0 B_0}{B_0' - 1}\)
from https://journals.aps.org/prb/pdf/10.1103/PhysRevB.28.5480. In this model there are four parameters:
name |
desc |
|---|---|
E_0 |
energy at the minimim |
B_0 |
bulk modulus |
B_0’ |
first derivative of the bulk modulus |
V_0 |
volume at the energy minimum |
We would like to find the value of these parameters that best fits the data above. That means, find the set of parameters that minimize the sum of the squared errors between the model and data.
First we need a function that will use the parameters and return the energy for a given volume.
def Murnaghan(parameters, vol):
"From PRB 28,5480 (1983)"
E0, B0, BP, V0 = parameters
# the backslash here means the line is contined on the next line.
# or use () around the whole expression
E = E0 + B0 * vol / BP * (((V0 / vol) ** BP) / (BP - 1) + 1) - V0 * B0 / (BP - 1.0)
return E
import numpy as np
Murnaghan((-56.45, 2, 1.2, 16.7), np.linspace(14, 18))
array([-55.95396512, -55.9854448 , -56.01576305, -56.04493457,
-56.07297374, -56.09989473, -56.12571141, -56.15043744,
-56.1740862 , -56.19667087, -56.21820436, -56.23869938,
-56.25816839, -56.27662367, -56.29407727, -56.31054101,
-56.32602655, -56.34054532, -56.35410858, -56.36672737,
-56.37841258, -56.38917489, -56.39902482, -56.40797271,
-56.41602873, -56.42320289, -56.42950503, -56.43494484,
-56.43953184, -56.44327541, -56.44618477, -56.44826902,
-56.44953708, -56.44999775, -56.4496597 , -56.44853145,
-56.4466214 , -56.4439378 , -56.4404888 , -56.43628241,
-56.43132653, -56.42562893, -56.41919727, -56.41203909,
-56.40416182, -56.39557278, -56.38627918, -56.37628814,
-56.36560665, -56.35424162])
Next, we need a function that computes the summed squared errors for a set of parameters. The use of squared errors is preferable in many cases to the absolute values because it has a continuous derivative. We will learn more about this later.
def objective(pars):
err = energies - Murnaghan(pars, volumes)
return np.sum(err**2) # we return the summed squared error directly
objective((-56.45, 2, 1.52, 16.0))
np.float64(0.15514191157778542)
Finally, we need an initial guess to start the minimization. As with all minimization problems, this can be the most difficult step. It is always a good idea to use properties of the model and data where possible to make these guesses. We have no way to plot anything in four dimensions, so we use analysis instead.
We can derive some of these from the data we have. First, we can get the minimum in energy and the corresponding volume that we know from the data. These are not the final answer, but they are a good guess for it.
The B0 parameter is related to the curvature at the minimum, which is the second derivative. We get that from repeated calls to numpy.gradient. Finally, \(B_0'\) is related to the derivative of \(B\) at the minimum, so we estimate that too.
imin = np.argmin(energies)
dedv = np.gradient(energies, volumes)
B = np.gradient(dedv, volumes)
Bp = np.gradient(B, volumes)
x0 = [energies[imin], B[imin], Bp[imin], volumes[imin]]
x0
[np.float64(-56.463),
np.float64(0.02575384116153356),
np.float64(-0.00900405886406903),
np.float64(17.23)]
Finally, we are ready to fit our function. As usual, we also plot the data and the fit for visual inspection.
from scipy.optimize import minimize
sol = minimize(objective, x0)
print(sol)
plt.plot(volumes, energies, "bo", label="Data")
vfit = np.linspace(min(volumes), max(volumes))
plt.plot(vfit, Murnaghan(sol.x, vfit), label="fit")
plt.legend()
plt.xlabel("V")
plt.ylabel("E");
message: Optimization terminated successfully.
success: True
status: 0
fun: 1.4912984000626383e-05
x: [-5.647e+01 5.723e-01 2.742e+00 1.656e+01]
nit: 28
jac: [-2.419e-06 -8.417e-07 3.751e-08 8.639e-07]
hess_inv: [[ 3.081e-01 -2.983e+00 7.646e+01 -2.454e+00]
[-2.983e+00 5.047e+01 -1.534e+03 4.746e+01]
[ 7.646e+01 -1.534e+03 6.851e+04 -2.867e+03]
[-2.454e+00 4.746e+01 -2.867e+03 1.553e+02]]
nfev: 175
njev: 35

That looks pretty good. We should ask ourselves, how do we know we got a minimum? We should see that the objective function is really at a minimum for each of the parameters. Here, we show that it is a minimum for the first parameter.
E0_range = np.linspace(0.9 * sol.x[0], 1.1 * sol.x[0])
_, b, c, d = sol.x
errs = [objective([e0, b, c, d]) for e0 in E0_range]
plt.plot(E0_range, errs)
plt.axvline(sol.x[0], c="k", ls="--")
plt.xlabel("E0")
plt.ylabel("summed squared error");

You can see visually that the error goes up on each side of the parameter estimate.
exercise Repeat this analysis for the other three parameters.
Later when we learn about linear algebra, we will learn that if you can show the eigenvalues of the Hessian of the objective function is positive definite, that also means you are at a minimum. It means the error goes up in any direction away from the minimum.
Usually we do some regression to find one of these:
Parameters for the model - because the parameters mean something
Properties of the model - because the properties mean something
In this particular case, we can do both. Some of the parameters are directly meaningful, like the E0, and V0 are the energy at the minimum, and the corresponding volume. B0 is also meaningful, it is called the bulk modulus, and it is a material property.
Now that we have a model though we can also define properties of it, e.g. in this case we have from thermodynamics that \(P = -dE/dV\). We can use our model to define this derivative. I use scipy.misc.derivative for this for convenience. The only issue with it is the energy function has arguments that are not in the right order for the derivative, so I make a proxy function here that just reverses the order of the arguments.
from scipy.misc import derivative
/tmp/ipykernel_2925/2127341723.py:1: DeprecationWarning: scipy.misc is deprecated and will be removed in 2.0.0
from scipy.misc import derivative
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[9], line 1
----> 1 from scipy.misc import derivative
ImportError: cannot import name 'derivative' from 'scipy.misc' (/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/scipy/misc/__init__.py)
def proxy(V0, pars0):
return Murnaghan(pars0, V0)
Murnaghan(sol.x, 16.5), proxy(16.5, sol.x)
(np.float64(-56.46833281366552), np.float64(-56.46833281366552))
from scipy.misc import derivative
pars = sol.x
def P(V):
def proxy(V0, pars0):
return Murnaghan(pars0, V0)
dEdV = derivative(proxy, V, args=(pars,), dx=1e-6)
return -dEdV
# Some examples
P(16), P(pars[-1]), P(18)
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[11], line 1
----> 1 from scipy.misc import derivative
2
3 pars = sol.x
4
ImportError: cannot import name 'derivative' from 'scipy.misc' (/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/scipy/misc/__init__.py)
The result above shows that it takes positive pressure to compress the material, the pressure is zero at the minimum, and it takes negative pressure to cause it to expand.
This example is just meant to illustrate what one can do with a model once you have it.
Parameter confidence intervals#
We have left out an important topic in the discussion above: How certain are we of the parameters we estimated? This is a complicated question that requires moderately sophisticated statistics to answer. We will build up to the solution in steps.
First, we recall that in a statistical sense we are estimating the values of the parameters. Specifically, we estimate the mean of the parameters, from a fixed number of data points.
Let’s say we have made 10 measurements that have an average of 16.1, and a standard deviation of 0.01. What is the range of values that we are 95% confident the next measurement will fall in?
We have to take into account the fact that we only have 10 measurements to make the estimation from, so the estimate is more uncertain than if we have 100 or 1000 measurements. The student t-tables tell us precisely how much more uncertain depending on the confidence level you want.
The point here is not for you to memorize or derive these formulas, only to illustrate that the uncertainty is not simply the standard deviation. It also includes the effect of the sample size.
from scipy.stats.distributions import t
n = 10 # number of measurements
dof = n - 1 # degrees of freedom
avg_x = 16.1 # average measurement
std_x = 0.01 # standard deviation of measurements
# Find 95% prediction interval for next measurement
alpha = 1.0 - 0.95
pred_interval = t.ppf(1 - alpha / 2.0, dof) * std_x / np.sqrt(n)
plus_side = avg_x + pred_interval
minus_side = avg_x - pred_interval
print(pred_interval)
print(
f"We are 95% confident the next measurement will be between {minus_side:1.3f} and {plus_side:1.3f}"
)
0.007153569059706646
We are 95% confident the next measurement will be between 16.093 and 16.107
To consider the uncertainty in model parameters, we need some way to estimate the standard deviation of the parameters. scipy.optimize.minimize does not provide much help with that. We will instead turn to scipy.optimize.curve_fit. This function will return information that is helpful in estimating the uncertainty. It is like scipy.optimize.minimize in the sense that it minimizes the summed squared errors between a model described in a function, and data defined in variables. Note in particular the docstring for the output variable pcov, which tells you how to compute the standard deviation errors on the parameters.
import numpy as np
from scipy.optimize import curve_fit
An example with curve_fit#
Given the data below, fit the following curve:
\(y(x) = \frac{a x}{b + x}\) to it.
That means, estimate the values of \(a, b\) that best fit the data.
import matplotlib.pyplot as plt
x = np.array([0.5, 0.387, 0.24, 0.136, 0.04, 0.011])
y = np.array([1.255, 1.25, 1.189, 1.124, 0.783, 0.402])
plt.plot(x, y, "bo")
plt.xlabel("x")
plt.ylabel("y");

What should we use for an initial guess? At \(x=0\), \(y = 0\), which isn’t that helpful. At large \(x\), we have \(y=a\). From the data, we can guess that \(a \approx 1.2\). For small x, we have \(y = a/b x\). So, if we estimate the slope, we can estimate b. We arrive at these guesses by thoughtful inspection of the data, and the model that we use to fit it.
x
array([0.5 , 0.387, 0.24 , 0.136, 0.04 , 0.011])
a0 = 1.2
m = np.gradient(y, x, edge_order=2) # m = a / b -> b = a / m
b0 = a0 / m[-1]
a0, b0
(1.2, np.float64(0.0781156032363354))
Now for the fitting.
# this is the function we want to fit to our data
def func(x, a, b):
return a * x / (b + x)
initial_guess = [a0, b0]
pars, pcov = curve_fit(func, x, y, p0=initial_guess)
print(pars)
print(pcov)
[1.32753143 0.02646156]
[[9.45332945e-05 7.10675660e-06]
[7.10675660e-06 1.05658847e-06]]
Always check the fit visually.
plt.plot(x, y, "bo")
xfit = np.linspace(0, 0.5)
plt.plot(xfit, func(xfit, *pars))
plt.xlabel("x")
plt.ylabel("y")
plt.legend(["data", "fit"])
plt.ylim([0, 2]);
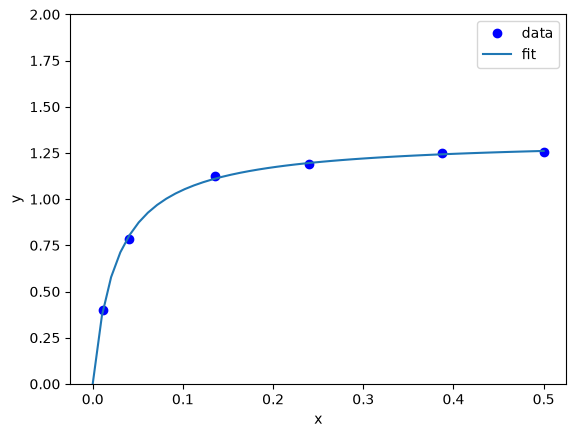
exercise Try different initial guesses and find one that does not look this good.
Uncertainty estimation#
Recall from the documentation of curve_fit that the standard deviation of each parameter is defined by:
pcov
array([[9.45332945e-05, 7.10675660e-06],
[7.10675660e-06, 1.05658847e-06]])
np.diag(pcov)
array([9.45332945e-05, 1.05658847e-06])
np.sqrt(np.diag(pcov))
array([0.00972282, 0.0010279 ])
We can use these to estimate confidence intervals on the two parameters. Note that here we still use the student-t multipliers to account for the uncertainty caused by having a small data set.
from scipy.stats.distributions import t
alpha = 0.05 # 95% confidence interval = 100*(1-alpha)
n = len(y) # number of data points
p = len(pars) # number of parameters
dof = max(0, n - p) # number of degrees of freedom
# student-t value for the dof and confidence level
tval = t.ppf(1.0 - alpha / 2.0, dof)
SERRS = np.sqrt(np.diag(pcov))
for i in range(2):
p = pars[i]
sigma = SERRS[i]
ci = sigma * tval
print(f"{p:1.3f} +/- {ci:1.3f}")
for i, p, var in zip(range(n), pars, np.diag(pcov)):
sigma = var**0.5
print(f"p{i}: {p:1.3f} [{p - sigma * tval:1.3f} {p + sigma * tval:1.3f}]")
1.328 +/- 0.027
0.026 +/- 0.003
p0: 1.328 [1.301 1.355]
p1: 0.026 [0.024 0.029]
The interpretation of this is that we do not know exactly what the parameters are, but we can be 95% confident that they fall in these ranges. These ranges do not include zero, so that is an indication that the parameters are significant.
It is not expected that you learn all the details above. They have been coded into the “Python computations in science and engineering” pycse package. This is not part of Anaconda; you have to install it yourself. You can pip install pycse.
After that, you can import the nlinfit command and use it to get confidence intervals directly.
from pycse import nlinfit
pars, pars_ci, se = nlinfit(func, x, y, [a0, b0], alpha=0.00001)
for i, par in enumerate(pars):
print(f"{par:1.3f}, {np.round(pars_ci[i], 3)}, {se[i]:1.4f}")
1.328, [1.058 1.598], 0.0097
0.026, [-0.002 0.055], 0.0010
It is important to realize that:
The size of the confidence interval depends on the number of parameters, data points, and desired confidence level.
The root of this is the minimization of an error function.
What about uncertainty on the predictions?#
Consider the fit again, and extrapolate it to larger \(x\):
plt.plot(x, y, "bo")
xfit = np.linspace(0, 5)
plt.plot(xfit, func(xfit, *pars))
plt.xlabel("x")
plt.ylabel("y")
plt.legend(["data", "fit"])
func(xfit, *pars)[-1]
np.float64(1.3205427042624864)

We estimate the model plateaus at about y=1.32, but what is an appropriate estimate of the error in this? There are uncertainties in the model parameters, so there must be uncertainty in the predictions. To estimate this, we first look at how to generate a distribution of random numbers with a normal distribution around some mean with some standard error.
p0_mean = pars[0]
p0_se = se[0]
p0_dist = np.random.normal(p0_mean, p0_se, 5000)
plt.hist(p0_dist, bins=20);

So the idea is we can generate a distribution of the parameters
p1_dist = np.random.normal(pars[1], se[1], 5000)
y5 = [func(5, p0, p1) for p0, p1 in zip(p0_dist, p1_dist)]
plt.hist(y5)
np.mean(y5), np.std(y5), se[1]
(np.float64(1.3205253385422204),
np.float64(0.009680495281111456),
np.float64(0.0010279048949675936))

Well, in 20/20 hindsight, we might have guessed the uncertainty in the asymptote would be just like the uncertainty in the \(a\) parameter. In this case, it is appropriate to use three significant figures given the uncertainty on the answer. A useful guideline is that the 95% confidence interval is about ± 2 σ. At ± 1 σ you only have about a 60% confidence interval.
print(f"At x=5, y={np.mean(y5):1.3f} +- {2 * np.std(y5):1.3f} at about the 95% confidence level.")
At x=5, y=1.321 +- 0.019 at about the 95% confidence level.
So we are not that uncertain after all in this case.
This method of error propagation is not perfect as it assumes the errors between the parameters are independent, and that they are normally distributed. However, the method is very simple to do, and simply relies on sampling the parameters from their respective distributions, and letting the results propagate naturally through the model. You do need to check for convergence with the sample size. This method is called a Monte Carlo propagation of errors.
Summary#
We covered a lot of ground today. The key points are:
Regression is a minimization of an accumulated error function.
If you need uncertainty on the parameters from a regression, use
pycse.nlinfit.If you need uncertainty on model predictions, you can either simulate it, or derive it. We will learn more about deriving it later.