
Integration in Python#
KEYWORDS: integration, trapz, cumtrapz, quad
Integration is used for many purposes in scientific problem solving. It can:
Represent the area under a curve or between curves
Solve differential equations
We may have data that represents a function that needs to be integrated, or a function we want to integrate, or a differential equation we want to solve. We may also have data that represents a some function, and that we wish to integrate.
Historically, we would have to look up or remember the formula for an integral, e.g. in a book like the 16th ed. CRC Standard Mathematical Tables, or tabulated in a page like http://integral-table.com/downloads/single-page-integral-table.pdf:
There are a limited number of known analytical integrals, and for everything else, we have to resort to numerical/computational approaches to evaluate them.
Numerical integration of data#
Data can be used to represent functions. Suppose we have the function \(y=x^2\), and 5 \(x\) values evenly spaced from 0 to 4. We can represent this function numerically with data like this.
import numpy as np
x = np.linspace(1, 4, 5)
y = x**2
import matplotlib.pyplot as plt
plt.plot(x, y, "bo--") # plot with blue circles connected by a dashed line
plt.xlabel("x")
plt.ylabel("y");
If we want the area under this curve, it is represented by:
\(A = \int_0^4 x^2 dx\)
We could analytically evaluate this as:
\(A = \frac{1}{3} (4^3 - 1^3)\).
Here is the analytical answer for future reference:
1 / 3 * (4**3 - 1**3)
21.0
It will not always be the case that we can evaluate the integrals analytically, and sometimes we just have the data, and not the analytical function it represents (e.g. if you have measured the data).
The classical way to compute the area under this curve is to use the trapezoid method. We know the area of a trapezoid is \(A = 0.5 * width * (y1 + y2)\). In this example, we have four trapezoids to compute the areas of.
To make this easier to compute, we need a few new ideas. First, it would be convenient to know how many elements are in the array x.
len(x)
5
Second, we need to know how to compute the area of a trapezoid defined by the points in x and y. The area of the first trapezoid is defined by:
0.5 * (y[0] + y[1]) * (x[1] - x[0])
np.float64(1.5234375)
What we would like to do is to loop over each trapezoid, compute the area, and accumulate it in a variable. Here is how we use a for loop to iterate from a value starting at 1 to the length of the array x. Note that although the length is 5, the last value of i is 4. The loop goes up to, but not including the last value of the range.
for i in range(1, len(x)):
print(i)
print("done")
1
2
3
4
done
x = np.linspace(1, 4, 1000)
y = x**2
area = 0.0 # variable we will accumulate the area in
for i in range(1, len(x)):
y1 = y[i - 1]
y2 = y[i]
width = x[i] - x[i - 1]
area += 0.5 * width * (y1 + y2) # increment the area variable
print(f"The estimated area is {area}.")
print(f"The exact area is {1 / 3 * (x[-1] ** 3 - x[0] ** 3)}")
The estimated area is 21.000004509013518.
The exact area is 21.0
plt.plot(x, y, "bo-");

Why don’t these agree? The trapezoid method is an approximation of the integral. In this case the straight lines connecting the points overestimate the value of the function, and so the area under this curve is overestimated.
Exercise: Increase the number of points slowly and see how the estimate converges to the exact value.
numpy.trapz#
It is somewhat tedious to write the loop above, making sure you get the indexing right, etc. The trapezoid method is defined in numpy. See the help for how to use it:
Now, we can perform the integration with just one line:
import numpy as np
x = np.linspace(1, 4, 5)
y = x**2
np.trapz(y, x)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[8], line 5
1 import numpy as np
2
3 x = np.linspace(1, 4, 5)
4 y = x**2
----> 5 np.trapz(y, x)
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/numpy/__init__.py:792, in __getattr__(attr)
789 import numpy.char as char
790 return char.chararray
--> 792 raise AttributeError(f"module {__name__!r} has no attribute {attr!r}")
AttributeError: module 'numpy' has no attribute 'trapz'
The trapezoid method is only exact for lines. For everything else, it is an approximation. For functions (or regions) that are concave up, the trapezoid method will over-estimate the integral, and for regions that are concave down, the method will underestimate the true integral.
The error in this method is formally:
\(error = - \frac{(b - a)^3}{12 N^2} f''(\xi)\)
In this formula, \(\xi\) is some number between \(a\) and \(b\), in other words the error is related to the second derivative of the function evaluated somewhere in the interval.
Practically, we only use this method for integrating data where we do not know the function it represents, so we cannot reliably estimate the error in the integral.
Simpson method https://docs.scipy.org/doc/scipy-0.18.1/reference/generated/scipy.integrate.simps.html#scipy.integrate.simps#
There are more advanced approximations to integration than the trapezoid method. With the trapezoid method, you essentially assume linear interpolation between the points, and in the limit of infinite points that are close together, this is reasonable. We rarely get to that limit however.
Instead of linear interpolation, we can use quadratic interpolation, where one uses the point and its neighbors to compute the equation of a parabola that goes through them, and then analytically computes the area under the parabola over the relevant interval. This is the basis of Simpson’s method. There is an excellent animation of Simpson’s Rule at that page.
Note in this case, since we integrate a parabola, the result is exact. It will not be exact in general, but this method is generally expected to be more accurate than the trapezoid method for well-behaved data because it represents the local curvature better than lines do.
from scipy.integrate import simps
simps(y, x)
---------------------------------------------------------------------------
ImportError Traceback (most recent call last)
Cell In[9], line 1
----> 1 from scipy.integrate import simps
2
3 simps(y, x)
ImportError: cannot import name 'simps' from 'scipy.integrate' (/opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/scipy/integrate/__init__.py)
Applications#
Estimating the volume of a solid#
We can use integrals to compute the volume of solids. If we know how the cross-sectional area of a solid varies in some direction, we simply evaluate the following integral:
\(\int_{x0}^{x1} A(x) dx\)
For a sphere, we can derive:
\(A(x) = \pi (1 - x^2)\)
R = 1
x = np.linspace(-R, R)
y = np.pi * (1 - x**2)
approx_V = simps(y, x)
exact_V = 4 / 3 * np.pi * R**3
print(f"""Approximate volume = {approx_V:1.4f}
Exact volume = {exact_V:1.4f}""")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[10], line 5
1 R = 1
2 x = np.linspace(-R, R)
3 y = np.pi * (1 - x**2)
4
----> 5 approx_V = simps(y, x)
6 exact_V = 4 / 3 * np.pi * R**3
7
8 print(f"""Approximate volume = {approx_V:1.4f}
NameError: name 'simps' is not defined
With 50 points, the estimate is pretty good. Try increasing the number of points to improve the estimate.
Estimating the volume of a plug flow reactor#
Adapted from Fogler example 2.7. The volume of a plug flow reactor is defined by this integral:
\(\int_{X0}^{X1} \frac{F_{A0}}{-r_A} dX\)
where \(F_{A0}\) is the inlet molar flow of species A, \(X\) is the conversion, and \(-r_A\) is the rate of generation of species A per unit volume. \(r_A\) is a function of conversion. We often do not know what the function is, but we can measure the rate of generation. Below is some tabulated data of the rate of generation of species A as a function of conversion.
X |
-r_A (kmol / m^3 / hr) |
|---|---|
0 |
39 |
0.2 |
53 |
0.4 |
59 |
0.6 |
38 |
0.65 |
25 |
Use this data to estimate the volume of the reactor required to achieve a conversion of 0.65.
X = np.array([0, 0.2, 0.4, 0.6, 0.65])
ra = -np.array([39, 53, 59, 38, 25])
Fa0 = 50 # kmol / hr.
V = simps(Fa0 / -ra, X)
print(f"The required volume is {V:1.3f} m^3.")
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[11], line 7
3 ra = -np.array([39, 53, 59, 38, 25])
4
5 Fa0 = 50 # kmol / hr.
6
----> 7 V = simps(Fa0 / -ra, X)
8
9 print(f"The required volume is {V:1.3f} m^3.")
NameError: name 'simps' is not defined
How does the volume depend on conversion? Let’s plot the integrand first so we can get a sense for how the area might change with conversion.
plt.plot(X, Fa0 / -ra)
plt.xlabel("Conversion")
plt.ylabel("$F_{A0} / -r_A$")
plt.xlim([0, 0.65])
plt.ylim([0, 2])
(0.0, 2.0)
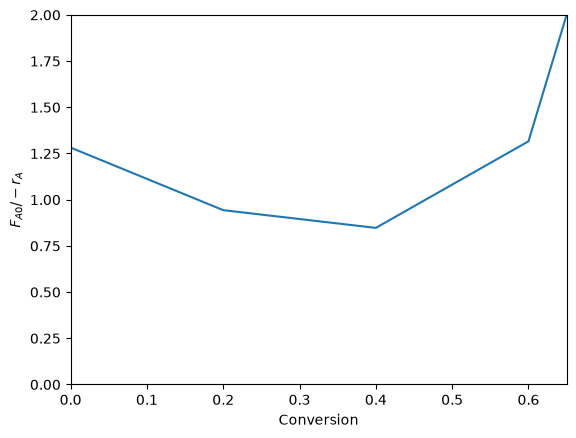
We could iterate over the conversions and print the volume for each value. This is a little wasteful since we recompute the areas in each iteration, but here it is so fast it does not matter.
Before jumping into the integration an loop, Let’s review array slicing. It allows us to select portions of arrays for analysis.
# X[start:below_end]
X = np.array([0, 0.2, 0.4, 0.6, 0.65])
X[0:3] # This selects points with indices 0-2
array([0. , 0.2, 0.4])
We use -1 for the last element (-2 for second to last element, etc). Note that this does not include the last element.
X[1:-1]
array([0.2, 0.4, 0.6])
To get to the last element, we do not specify an end value like this:
X[1:]
array([0.2 , 0.4 , 0.6 , 0.65])
So, back to the integration. We need to use slices of the array for each integration step.
y = Fa0 / -ra
volumes = [] # empty list to store values in
for i in range(0, len(X)):
vol = np.trapz(y[0 : i + 1], X[0 : i + 1])
volumes += [vol] # here we accumulate the vol into our list
print(f"At X={X[i]:3.2f} V={vol:1.3f} m^3")
plt.plot(X, volumes)
plt.xlabel("X")
plt.ylabel("V (m^3)")
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[16], line 6
2
3 volumes = [] # empty list to store values in
4
5 for i in range(0, len(X)):
----> 6 vol = np.trapz(y[0 : i + 1], X[0 : i + 1])
7 volumes += [vol] # here we accumulate the vol into our list
8 print(f"At X={X[i]:3.2f} V={vol:1.3f} m^3")
9
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/numpy/__init__.py:792, in __getattr__(attr)
789 import numpy.char as char
790 return char.chararray
--> 792 raise AttributeError(f"module {__name__!r} has no attribute {attr!r}")
AttributeError: module 'numpy' has no attribute 'trapz'
y = Fa0 / -ra
volumes = np.empty(len(y)) # empty list to store values in
for i in range(0, len(X)):
vol = np.trapz(y[0 : i + 1], X[0 : i + 1])
volumes[i] = vol # store volume by index
print(f"At X={X[i]:3.2f} V={vol:1.3f} m^3")
print(volumes)
plt.plot(X, volumes)
plt.xlabel("X")
plt.ylabel("V (m^3)")
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[17], line 6
2
3 volumes = np.empty(len(y)) # empty list to store values in
4
5 for i in range(0, len(X)):
----> 6 vol = np.trapz(y[0 : i + 1], X[0 : i + 1])
7 volumes[i] = vol # store volume by index
8 print(f"At X={X[i]:3.2f} V={vol:1.3f} m^3")
9
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/numpy/__init__.py:792, in __getattr__(attr)
789 import numpy.char as char
790 return char.chararray
--> 792 raise AttributeError(f"module {__name__!r} has no attribute {attr!r}")
AttributeError: module 'numpy' has no attribute 'trapz'
An alternative approach is to use a cumulative trapezoid function. This is defined in scipy.integrate. The main benefit of this approach is that it is faster, as it does not recompute the areas, and the code is shorter, so there are less places to make mistakes!
import scipy as sp
cumV = sp.integrate.cumtrapz(Fa0 / -ra, X)
plt.plot(X[1:], cumV, "bo-")
plt.xlabel("Conversion")
plt.ylabel("Volume (m$^3$)")
cumV
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[18], line 3
1 import scipy as sp
2
----> 3 cumV = sp.integrate.cumtrapz(Fa0 / -ra, X)
4
5 plt.plot(X[1:], cumV, "bo-")
6 plt.xlabel("Conversion")
AttributeError: module 'scipy.integrate' has no attribute 'cumtrapz'
What if you want to know the volume required for an intermediate conversion? For that you need interpolation. We will cover that later in the course when we talk more about dealing with data.
Numerical quadrature - or integration of functions#
When you have a function and you know its analytical form we can use quadrature to estimate integrals of it. In quadrature, we approximate the integral as a weighted sum of function values. By increasing the number values used, we can systematically improve the integral estimates.
To motivate the idea, let’s consider the function integral of \(y(x) = 7 x^3 - 8 x^2 - 3x +3\) from -1 to 1.
This is a third order polynomial, so we can in this case replace the integral with a sum of two points:
\(\int f(x) dx = w_1 f(x_1) + w_2 f(x_2)\)
provided we can find the weights, and the right values of \(x\) to use. These are derived and tabulated (e.g. at https://en.wikipedia.org/wiki/Gaussian_quadrature), which tells us for this case, the weights are simply equal to one, and we should use \(\pm \sqrt{1/3}\) for x.
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-1, 1)
def f(x):
return 7 * x**3 - 8 * x**2 - 3 * x + 3
plt.plot(x, f(x))
print("gaussian quadrature: ", f(np.sqrt(1 / 3)) + f(-np.sqrt(1 / 3)))
def integral(x):
return 7 / 4 * x**4 - 1 / 3 * 8 * x**3 - 3 / 2 * x**2 + 3 * x
integral(1) - integral(-1)
gaussian quadrature: 0.6666666666666674
0.6666666666666674

This example is special in several ways:
The formula was derived for nth order polynomials, here we had a 3rd order polynomial, so n-1 points are needed to exactly compute the integral. The formula is not exact for non-polynomial functions. For non-poynomial functions, the formula is an approximation to the integral and you have to use more than two points to estimate the integral. When you use more points, the weights change, but they can be looked up in the table, or computed.
I show this example mostly to motivate the idea that given a function, you can perform an integral by evaluating the function at special points, and weighting those function values appropriately. In practice, we don’t do this manually. It has been coded already into robust libraries that we can reuse.
scipy.integrate provides the quad function. This is a Python wrapper around a sophisticated Fortran library for integrating functions. These routines use an adaptive method to compute the integral and provide an upper bound on the error of the computed integral. The beauty of this interface is we can use a reliable, proven library written in Fortran inside of Python. We do not have to write and compile a Fortran program ourselves.
from scipy.integrate import quad
We return to our simple integral, which should equal 21.
4**3 / 3 - 1 / 3 # analytical integral of x^2 from 1 to 4.
21.0
To use the quad function, we define a function, and use it as the first argument in the quad function. The quad function returns the integral value, and estimated error.
def f(x):
return x**2
a, b = 1, 4
I, err = quad(f, a, b)
I
from IPython.display import Latex
Latex(f"$\int_{a}^{b} x^2 dx = {I}$")
We can recompute the volume of a sphere much more precisely, and easily now. Recall \(A(x) = \pi (1 - x^2)\) and that \(V = \int_{-1}^{1} A(x) dx\). Here is the implementation.
def cross_section(x):
return np.pi * (1 - x**2)
quad(cross_section, -1, 1)
(4.1887902047863905, 4.6504913306781755e-14)
We can integrate to infinity.
\(\int_{-\infty}^{\infty} \frac{1}{x^2 + 1} = \pi\).
Let us verify this. You can use ± ∞ as limits.
def f(x):
return 1 / (x**2 + 1)
quad(f, -np.inf, np.inf)
(3.141592653589793, 5.155583041103855e-10)
Not all integrals are finite. For example
\(\int_1^\infty \frac{dx}{x} = \infty\)
Here we get an IntegrationWarning that a maximum number of subdivisions has been achieved.
def f(x):
return 1 / x
quad(f, 1, np.inf)
/tmp/ipykernel_2715/1566401794.py:5: IntegrationWarning: The maximum number of subdivisions (50) has been achieved.
If increasing the limit yields no improvement it is advised to analyze
the integrand in order to determine the difficulties. If the position of a
local difficulty can be determined (singularity, discontinuity) one will
probably gain from splitting up the interval and calling the integrator
on the subranges. Perhaps a special-purpose integrator should be used.
quad(f, 1, np.inf)
(40.996012819169536, 8.156214940493651)
Math is fun though, this subtly different function is integrable:
def f(x):
return 1 / x**2
quad(f, 1, np.infty)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[26], line 5
1 def f(x):
2 return 1 / x**2
3
4
----> 5 quad(f, 1, np.infty)
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/numpy/__init__.py:778, in __getattr__(attr)
775 raise AttributeError(__former_attrs__[attr], name=None)
777 if attr in __expired_attributes__:
--> 778 raise AttributeError(
779 f"`np.{attr}` was removed in the NumPy 2.0 release. "
780 f"{__expired_attributes__[attr]}",
781 name=None
782 )
784 if attr == "chararray":
785 warnings.warn(
786 "`np.chararray` is deprecated and will be removed from "
787 "the main namespace in the future. Use an array with a string "
788 "or bytes dtype instead.", DeprecationWarning, stacklevel=2)
AttributeError: `np.infty` was removed in the NumPy 2.0 release. Use `np.inf` instead.
And this function is integrable, despite the singularity at x=0.
def f(x):
return 1 / np.sqrt(x)
quad(f, 0, 1)
(1.9999999999999984, 5.773159728050814e-15)
Find the volume of a PFR#
For a single reaction that consumes a species A at a rate of \(-r_A = k C_A\), a mole balance leads to an equation for the volume as a function of conversion \(X\) as:
\(V = \int_0^X \frac{F_{A0}}{-r_A(X)} dX\)
\(F_{A0}\) is the inlet molar flow of species A, which is equal to the inlet concentration times the inlet volumetric flow. The concentration of A in the reactor is a function of the conversion, and is given by \(C_A = C_{A0} (1 - X)\). If \(k = 0.23\) 1/min, \(C_{A0} = 1\) mol/L, and the volumetric flow is 1 L/min, what is the reactor volume required to achieve a conversion of 50%?
from scipy.integrate import quad
k = 0.23
Ca0 = 1.0
v0 = 1.0
Fa0 = v0 * Ca0
def rA(X):
Ca = Ca0 * (1 - X)
return -k * Ca
def integrand(X):
return Fa0 / -rA(X)
vol, err = quad(integrand, 0, 0.5)
print(f"The required volume is {vol:1.3f} L")
The required volume is 3.014 L
Diffusion#
When the surface concentration of a solute is constant, and the solute diffused into a semi-infinite solid, the concentration of the solute in the solid varies with space and time according to: \(C_A(x, t) = C_{As} - (C_{As} - C_{A0}) erf\left(\frac{x}{\sqrt{4 D t}}\right)\).
\(C_{As}\) is the concentration of the diffusing species at \(x=0\), and \(C_{A0}\) is the initial concentration of the species in the semi-infinite body.
and \(erf(x) = \frac{2}{\sqrt{\pi}} \int_0^x e^-{\xi^2} d\xi\)
This integral arises from the solution to the differential equation describing diffusion. The integral does not have an analytical solution, but it can be solved numerically.
Suppose we have a steel sample #1 that initially contains 0.02% Carbon in it, and it is put in contact with another steel containing 1.2% carbon. If the diffusion coefficient of carbon is 1.54e-6 cm^2/s, what will the concentration of carbon in sample #1 be after 24 hours at a distance of 0.15 cm from the interface?
Cas = 1.2
Ca0 = 0.02
D = 1.54e-6 # cm^2/s
X = 0.15 # cm
t = 24 * 60 * 60 # time in seconds
xi = X / np.sqrt(4 * D * t)
def erf_integrand(xi):
return 2 / np.sqrt(np.pi) * np.exp(-(xi**2))
erfx, err = quad(erf_integrand, 0, xi)
Cx = Cas - (Cas - Ca0) * erfx
print(f"The concentration of carbon at X = {X} cm after {t / 3600} hours is {Cx:1.2f}%.")
The concentration of carbon at X = 0.15 cm after 24.0 hours is 0.93%.
The error function, \(erf(x)\) is such an important function it is implemented as a special function in scipy.special.
from scipy.special import erf
Cx_wspecial = Cas - (Cas - Ca0) * erf(xi)
print(f"The concentration of carbon at X = {X} cm after {t / 3600} hours is {Cx_wspecial:1.2f}%.")
The concentration of carbon at X = 0.15 cm after 24.0 hours is 0.93%.
Summary#
The main points of this lecture were on
Numerical integration of data
I recommend you rely on library implementations of the trapezoid method or Simpson’s method where possible.
numpy.trapz,scipy.integrate.cumtrapz, andscipy.integrate.simps.
Integration of functions by quadrature
quadrature uses a weighted sum of function evaluations to estimate the integrals.
I recommend you rely on a library implementation of a quadrature
e.g.
scipy.integrate.quad.These libraries provide sophisticated convergence algorithms and error estimates
Next time we will consider using integration to obtain solutions to differential equations.