
Applications of linear algebra#
KEYWORDS: numpy.linalg.solve
Linear algebra is used extensively in engineering applications. Here we consider some examples.
Application in reaction engineering - Steady state CSTR#
Suppose we have first order reactions occurring in a CSTR. We can represent the concentrations of each species in the reactor as a vector: \(C = [C_A, C_C, C_D, ...]\).
Let the reactions be \(A \rightarrow C\) and \(C \rightarrow D\). These reactions happen at these rates:
\(r_1 = k_1 C_A\) and \(r_2 = k_2 C_C\).
We assume a constant volume \(V\), and volumetric flow rate \(\nu\) into a CSTR, and steady state. It is convenient to define \(\tau = V / \nu\). With these assumptions, we can derive the following species mole balances:
\(0 = C_{A, feed} - C_A - \tau k_1 C_A\)
\(0 = C_{C, feed} - C_C + \tau k_1 C_A - \tau k_2 C_C\)
\(0 = C_{D, feed} - C_D + \tau k_2 C_C\)
These are not particularly in a useful form, since they do not resemble \(\mathbf{A} \mathbf{x} = \mathbf{b}\). We can rearrange them to achieve that. We need all the variables on the left, and any constant terms on the right.
\(C_A + \tau k_1 C_A = C_{A, feed}\)
\(C_C - \tau k_1 C_A + \tau k_2 C_C = C_{C, feed}\)
\(C_D - \tau k_2 C_C = C_{D, feed}\)
Now, we can start to see some structure emerge. Let \(\mathbf{C} = [C_A, C_C, C_D]\).
Let \(\mathbf{A} = \left[\begin{array}{ccc} 1 + \tau k_1 & 0 & 0 \\ -\tau k_1 & 1 + \tau k_2 & 0 \\ 0 & -\tau k_2 & 1 \end{array}\right]\)
and finally, we have \(\mathbf{C_{feed}} = [C_{A,feed}, C_{C, feed}, C_{D, feed}]\). Or, all together:
\(\mathbf{A} \mathbf{C} = \mathbf{C_{feed}}\).
Note that we have been talking about these as linear equations, but, we may also think of them as transformations. Consider this:
\(\mathbf{A}^{-1} \mathbf{C_{feed}} = \mathbf{C}\).
Here we can see that \(\mathbf{A}^{-1}\) transforms the feed concentrations into the exit concentrations.
Solving these equations is now straightfoward:
import numpy as np
tau = 2.5 # Residence time (min)
C_feed = [2.2, 0.0, 0.0] # mol / L
k1 = 2.3 # 1/min
k2 = 4.5 # 1/min
A = np.array([[1 + tau * k1, 0.0, 0.0], [-tau * k1, 1 + tau * k2, 0.0], [0.0, -tau * k2, 1]])
C_A, C_C, C_D = np.linalg.solve(A, C_feed)
print(f"The exit concentrations are C_A={C_A:1.2f}, C_C={C_C:1.2f}, C_D={C_D:1.2f} mol/L")
The exit concentrations are C_A=0.33, C_C=0.15, C_D=1.72 mol/L
A x = b
A.inv A x = A.inv b
x = A.inv b
np.linalg.inv(A) @ C_feed
array([0.32592593, 0.15298564, 1.72108844])
Finding independent reactions#
reference: Exercise 2.4 in Chemical Reactor Analysis and Design Fundamentals by Rawlings and Ekerdt.
The following reactions are proposed in the hydrogenation of bromine. The reactions are defined by \(\mathbf{M} \mathbf{v}\) where \(\mathbf{M}\) is a stoichometric matrix in which each row represents a reaction with negative stoichiometric coefficients for reactants, and positive stoichiometric coefficients for products. A stoichiometric coefficient of 0 is used for species not participating in the reaction. The species vector is \(\mathbf{v}\) = [H2 H Br2 Br HBr].T
# [H2 H Br2 Br HBr]
M = np.array(
[
[-1, 0, -1, 0, 2], # H2 + Br2 == 2HBR
[0, 0, -1, 2, 0], # Br2 == 2Br
[-1, 1, 0, -1, 1], # Br + H2 == HBr + H
[0, -1, -1, 1, 1], # H + Br2 == HBr + Br
[1, -1, 0, 1, -1], # H + HBr == H2 + Br
[0, 0, 1, -2, 0],
]
) # 2Br == Br2
We can check to see how many independent rows there are, this is equal to the rank of the matrix.
np.linalg.matrix_rank(M)
np.int64(3)
You can see based on this result that there are only three independent equations. Now we consider how to identify three of them. We need to manipulate \(\mathbf{M}\) to eliminate at least three rows. We can see by inspection that rows 1 and 5 are linearly related. If we add row 1 to row 5, we will get a row of zeros. That means these two rows are linearly independent.
M[5] += M[1]
M
array([[-1, 0, -1, 0, 2],
[ 0, 0, -1, 2, 0],
[-1, 1, 0, -1, 1],
[ 0, -1, -1, 1, 1],
[ 1, -1, 0, 1, -1],
[ 0, 0, 0, 0, 0]])
Further inspection shows Row 0 is the sum of rows 2 and 3.
M[0] -= M[2] + M[3]
M
array([[ 0, 0, 0, 0, 0],
[ 0, 0, -1, 2, 0],
[-1, 1, 0, -1, 1],
[ 0, -1, -1, 1, 1],
[ 1, -1, 0, 1, -1],
[ 0, 0, 0, 0, 0]])
Finally reaction 2 is the opposite of reaction 4
M[2] += M[4]
M
array([[ 0, 0, 0, 0, 0],
[ 0, 0, -1, 2, 0],
[ 0, 0, 0, 0, 0],
[ 0, -1, -1, 1, 1],
[ 1, -1, 0, 1, -1],
[ 0, 0, 0, 0, 0]])
We have successfully eliminated three reactions by linear combinations of other reactions. We can reorder the array like this to put the non-zero rows at the top.
M[[1, 3, 4, 0, 2, 5]]
array([[ 0, 0, -1, 2, 0],
[ 0, -1, -1, 1, 1],
[ 1, -1, 0, 1, -1],
[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0],
[ 0, 0, 0, 0, 0]])
We can print these in a more readable form like this:
labels = ["H2", "H", "Br2", "Br", "HBr"]
for row in M:
if not np.all(row == 0): # ignore rows that are all zeros
s = "0 = "
for i, nu in enumerate(row):
if nu != 0:
s += f" {int(nu):+d}{labels[i]}"
print(s)
0 = -1Br2 +2Br
0 = -1H -1Br2 +1Br +1HBr
0 = +1H2 -1H +1Br -1HBr
That representation is a little clunky, but it is tricky to get more conventional looking reactions:
labels = ["H2", "H", "Br2", "Br", "HBr"]
for row in M:
if not np.all(row == 0): # skip rows of all zeros
reactants, products = [], []
for nu, species in zip(row, labels):
if nu < 0:
reactants += [f" {'' if nu == -1 else -int(nu)}{species}"]
elif nu > 0:
products += [f" {'' if nu == 1 else int(nu)}{species}"]
reactants = " + ".join(reactants)
products = " + ".join(products)
print(f"{reactants:12s} -> {products:20s}")
Br2 -> 2Br
H + Br2 -> Br + HBr
H + HBr -> H2 + Br
What we did by hand was to put the matrix into reduced row echelon form. It is not common to do this by hand. One way to get the computer to do this for you is to use sympy. This is a symbolic math package for Python that is similar to Mathematica and Maple in its ability to do symbolic (as opposed to numeric) manipulations.
import sympy
import sympy
M = sympy.Matrix(M)
reduced_form, inds = M.rref()
reduced_form
labels = ["H2", "H", "Br2", "Br", "HBr"]
for row in np.array(reduced_form).astype(np.float):
if not np.all(row == 0): # skip rows of all zeros
reactants, products = [], []
for nu, species in zip(row, labels):
if nu < 0:
reactants += [f" {'' if nu == -1 else -int(nu)}{species}"]
elif nu > 0:
products += [f" {'' if nu == 1 else int(nu)}{species}"]
reactants = " + ".join(reactants)
products = " + ".join(products)
print(f"{reactants:12s} -> {products:20s}")
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[13], line 2
1 labels = ["H2", "H", "Br2", "Br", "HBr"]
----> 2 for row in np.array(reduced_form).astype(np.float):
3 if not np.all(row == 0): # skip rows of all zeros
4 reactants, products = [], []
5 for nu, species in zip(row, labels):
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/numpy/__init__.py:775, in __getattr__(attr)
770 warnings.warn(
771 f"In the future `np.{attr}` will be defined as the "
772 "corresponding NumPy scalar.", FutureWarning, stacklevel=2)
774 if attr in __former_attrs__:
--> 775 raise AttributeError(__former_attrs__[attr], name=None)
777 if attr in __expired_attributes__:
778 raise AttributeError(
779 f"`np.{attr}` was removed in the NumPy 2.0 release. "
780 f"{__expired_attributes__[attr]}",
781 name=None
782 )
AttributeError: module 'numpy' has no attribute 'float'.
`np.float` was a deprecated alias for the builtin `float`. To avoid this error in existing code, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
Note that a Matrix is not the same as an array. You can convert it to one like this:
np.array(reduced_form).astype(np.float)
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[14], line 1
----> 1 np.array(reduced_form).astype(np.float)
File /opt/hostedtoolcache/Python/3.11.15/x64/lib/python3.11/site-packages/numpy/__init__.py:775, in __getattr__(attr)
770 warnings.warn(
771 f"In the future `np.{attr}` will be defined as the "
772 "corresponding NumPy scalar.", FutureWarning, stacklevel=2)
774 if attr in __former_attrs__:
--> 775 raise AttributeError(__former_attrs__[attr], name=None)
777 if attr in __expired_attributes__:
778 raise AttributeError(
779 f"`np.{attr}` was removed in the NumPy 2.0 release. "
780 f"{__expired_attributes__[attr]}",
781 name=None
782 )
AttributeError: module 'numpy' has no attribute 'float'.
`np.float` was a deprecated alias for the builtin `float`. To avoid this error in existing code, use `float` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.float64` here.
The aliases was originally deprecated in NumPy 1.20; for more details and guidance see the original release note at:
https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
From here you can use the code from above to construct the equations.
Application in linear boundary value problems#
Let us consider pressure driven flow again.
\(\frac{d^2 v_x}{dy^2} = \frac{1}{\mu}\frac{\Delta P}{\Delta x}\)
This is a boundary value problem where \(v_x(y=0) = 0\) and \(v_x(y=B) = 0\). The solution is well-known and parabolic.
We previously used scipy.integrate.solve_bvp for this. Recall that it is necessary to create an initial guess of the solution, and that can be tricky. Here we consider an alternative approach to solving it using a method of finite differences.
We can write the second derivative as an approximate finite difference formula:
\(f''(x) \approx \frac{f(x + h) - 2 f(x) + f(x-h)}{h^2}\)
Let’s discretize the domain and then see if we can solve for the velocity at the discretized points.
At each point, we can estimate the second derivative as:
\(\frac{d^2 v}{dy^2} \approx \frac{v_{j+1} - 2 v_j + v_{j-1}}{h^2} = \frac{\Delta P}{\mu\Delta x}\)
How does this help us? The \(v_j\) are variables that we want to solve for. With a little rearrangement we have:
\(v_{j+1} - 2 v_j + v_{j-1} = \frac{h^2 \Delta P}{\mu\Delta x} = G\)
Let’s write a few of these out, starting at \(j=1\) up to \(j=N-1\):
\(v_2 - 2 v_1 + v_0 = G\)
\(v_3 - 2 v_2 + v_1 = G\)
…
\(v_{N} - 2 v_{N-1} + v_{N-2} = G\)
If we define \(\mathbf{v} = [v_1, v_2, ... v_{N-1}]\) (remember we know \(v_0\) and \(v_{N}\) from the boundary conditions), we can see the following structure emerge:
Let \(\mathbf{A} = \left[\begin{array}{ccccc} -2 & 1 & 0 & ... & 0 \\ 1 & -2 & 1 & ...& 0\\ \vdots\\ 0 & ... & 0 & 1 & -2 \end{array}\right]\)
This matrix is sparse (most entries are zero), and diagonal. The diagonal is always -2, and the diagonal above and below the main diagonal is always 1. Note that some derivations of this move a minus sign into the \(\mathbf{G}\), but it does not change anything. Let’s consider how to construct a matrix like this.
A = np.eye(5) * -2
L = np.diag(np.ones(4), -1)
U = np.diag(np.ones(4), 1)
A + L + U
array([[-2., 1., 0., 0., 0.],
[ 1., -2., 1., 0., 0.],
[ 0., 1., -2., 1., 0.],
[ 0., 0., 1., -2., 1.],
[ 0., 0., 0., 1., -2.]])
# Alternative way to make the A matrix
A = np.zeros((5, 5))
for i in range(5):
for j in range(5):
if i == j:
A[i, j] = -2
elif i - j == 1:
A[i, j] = 1
elif j - i == 1:
A[i, j] = 1
A
array([[-2., 1., 0., 0., 0.],
[ 1., -2., 1., 0., 0.],
[ 0., 1., -2., 1., 0.],
[ 0., 0., 1., -2., 1.],
[ 0., 0., 0., 1., -2.]])
And we can define \(\mathbf{G} = [G - v_0, G, G, ..., G - v_N]\) so that we have the following linear equation that is easy to solve:
\(\mathbf{A} \mathbf{v} = \mathbf{G}\). The only issue is how to code this up conveniently?
B = 0.2
N = 100 # You need to use enough points to make sure the derivatives are
# reasonably approximated
y, h = np.linspace(0, B, N, retstep=True)
# We only define the grid points on the inside. v0, vn are the boundary conditions.
A = np.eye(len(y) - 2) * -2
L = np.diag(np.ones(len(y) - 3), -1) # lower diagonal
U = np.diag(np.ones(len(y) - 3), 1) # upper diagonal
A = A + L + U
A # always a good idea to check we have the right structure.
array([[-2., 1., 0., ..., 0., 0., 0.],
[ 1., -2., 1., ..., 0., 0., 0.],
[ 0., 1., -2., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., -2., 1., 0.],
[ 0., 0., 0., ..., 1., -2., 1.],
[ 0., 0., 0., ..., 0., 1., -2.]], shape=(98, 98))
Now we create the \(\mathbf{G}\) vector.
mu = 2
deltaPx = -50
v0 = vB = 0.0
G = np.ones(len(y) - 2) * deltaPx / mu * h**2
G[0] -= v0
G[-1] -= vB
Now, solving this is simple, no initial guesses required since it is a linear problem.
vx = np.linalg.solve(A, G)
import matplotlib.pyplot as plt
plt.plot(y, np.concatenate([[v0], vx, [vB]]), "b.") # concatenate is to add the BCS to the solution
plt.xlabel("y")
plt.ylabel("$v_x$")
plt.xlim([0, B])
plt.ylim([0, 0.15]);
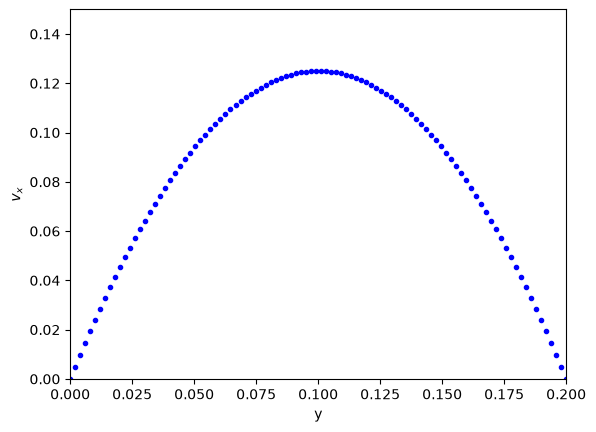
Note that we have approximated the solution by discretizing and estimating the derivatives that the points. You have to check for convergence by increasing the number of points \(N\).
This method worked because the BVP was linear, i.e. no products, powers, etc of derivatives, so that the final set of equations after discretization was linear. If the BVP was nonlinear, we would end up with a set of coupled nonlinear equations that you would have to use scipy.optimize.fsolve to solve, or scipy.integrate.solve_bvp, and these would both require an initial guess to solve.
Things to look out for#
Just because systems are linear doesn’t mean they are well-behaved. Seemingly simple equations can show unexpected behavior. Consider
\(-0.5 x1 + x2 = 1.1\)
and
\(-0.46 x1 + x2 = 1.0\)
These are easy to solve.
import numpy as np
A = np.array([[-0.5, 1], [-0.4999999999, 1]])
b = np.array([1.001, 1])
np.linalg.solve(A, b), np.linalg.det(A)
(array([-9999999.17259463, -4999998.58529732]),
np.float64(-1.000000082740374e-10))
Now consider this slightly different system where we just change -0.46 to -0.47. Surely that should not be a big deal right?
A = np.array([[-0.5, 1], [-0.47, 1]])
b = np.array([1.1, 1])
np.linalg.solve(A, b)
array([-3.33333333, -0.56666667])
That seems like a big change in the answer for such a small change in one coefficient. What is happening? The determinant of this matrix is small, and the condition number is high, which means it is an ill-conditioned system of equations.
np.linalg.det(A), np.linalg.cond(A)
(np.float64(-0.030000000000000023), np.float64(82.35119021800712))
Graphically, this means the two lines are nearly parallel, so even the smallest shift in the slope will result in a large change in the intersection.
import matplotlib.pyplot as plt
x1 = np.linspace(-6, 0)
x2_0 = 1.1 + 0.5 * x1
x2_1 = 1.0 + 0.47 * x1
plt.plot(x1, x2_0, x1, x2_1)
plt.xlabel("x1")
plt.ylabel("x2");
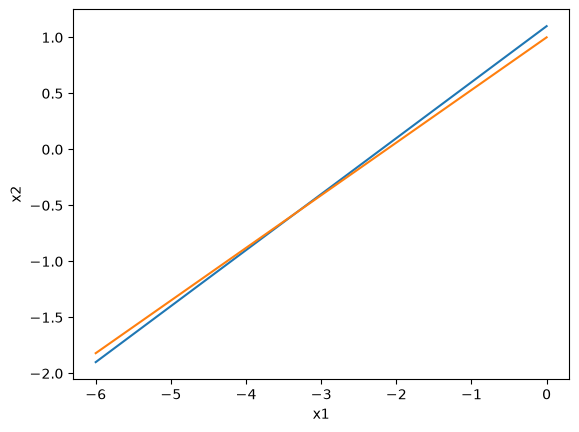
This system of equations is sensitive to roundoff errors, both in the coefficients of \(\mathbf{A}\) and in the numerics of solving the equations.
Leveraging linear algebra for iteration#
Linear algebra can be used for iteration (for loops) in some cases. Doing this is usually faster because dedicated linear algebra libraries are very fast, and the code is usually shorter. However, it is trickier to write sometimes, and not everything can be done this way.
It can also be advantageous to use this approach in machine learning. Some frameworks are difficult to use loops in.
The dot product is defined as:
\(\mathbf{a}\cdot\mathbf{b} = \sum_{i=0}^{N-1} a_i b_i\)
For specificity we have these two vectors to start with:
import numpy as np
a = np.array([1, 2, 3, 4, 5])
b = np.array([3, 6, 8, 9, 10])
As defined, we could implement the dot product as:
dp = 0
for i in range(len(a)):
dp += a[i] * b[i]
dp
np.int64(125)
We can do better than that with elementwise multiplication:
np.sum(a * b)
np.int64(125)
The best approach, however, is the linear algebra approach:
a @ b, np.dot(a, b)
(np.int64(125), np.int64(125))
Why is this better?
It is short.
It does not specify how the computation is done. This allows it to be done with an optimized (i.e. fast) and possibly parallelized algorithm. Many very smart people have worked hard to make linear algebra fast; we should try not to implement it ourselves.
Consider \(y = \sum\limits_{i=1}^n w_i x_i^2\). This operation is like a weighted sum of squares.
The old-fashioned way to do this is with a loop.
w = np.array([0.1, 0.25, 0.12, 0.45, 0.98])
x = np.array([9, 7, 11, 12, 8])
y = 0
for wi, xi in zip(w, x):
y += wi * xi**2
y
np.float64(162.39)
Compare this to the more modern numpy approach.
y = np.sum(w * x**2)
We can also express this in matrix algebra form. The operation is equivalent to \(y = \mathbf{x} \cdot \mathbf{D_w} \cdot \mathbf{x}^T\) where \(\mathbf{D_w}\) is a diagonal matrix with the weights on the diagonal.
x @ np.diag(w) @ x
np.float64(162.39000000000001)
Finally, consider the sum of the product of three vectors. Let \(y = \sum\limits_{i=1}^n w_i x_i y_i\). This is like a weighted sum of products.
w = np.array([0.1, 0.25, 0.12, 0.45, 0.98])
x = np.array([9, 7, 11, 12, 8])
y = np.array([2, 5, 3, 8, 0])
print(np.sum(w * x * y)) # numpy vectorized approach
w @ np.diag(x) @ y # linear algebra approach
57.71
np.float64(57.71)
np.vdot(a, b), np.dot(a, b)
(np.int64(125), np.int64(125))
Summary#
In this lecture we considered several applications of linear algebra including:
Solutions to steady state mass balances
Finding independent reactions
Solving linear boundary value problems
We also briefly touched on vectorized approaches to using linear algebra to avoid writing explicit loops.