
Introduction to automatic differentiation#
KEYWORDS: autograd
Note
autograd has largely been replaced by jax and pytorch today (2023). autograd is still the easiest starting point in my opinion, so I am leaving this as it is.
Automatic differentiation is the automated application of the chain rule to computer programs to compute derivatives. It is the centerpiece technology in machine learning that enables the “training” or optimization of model parameters to best fit data. We introduce it here in the context of science and engineering applications.
Mathematical, scientific and engineering applications of autograd#
Evaluating line integrals#
A line integral is an integral of a function along a curve in space. We usually represent the curve by a parametric equation, e.g. \(\mathbf{r}(t) = [x(t), y(t), z(t)] = x(t)\mathbf{i} + y(t)\mathbf{j} + z(t)\mathbf{k}\). So, in general the curve will be a vector function, and the function we want to integrate will also be a vector function.
Then, we can write the line integral definition as:
\(\int_C \mathbf{F(r)} \cdot d\mathbf{r} = \int_a^b \mathbf{F}(\mathbf{r}(t)) \cdot \mathbf{r'}(t) dt\) where \(\mathbf{r'}(t) = \frac{d\mathbf{r}}{dt}\). This integrand is a scalar function, because of the dot product.
The following examples are adapted from Chapter 10 in Advanced Engineering Mathematics by Kreysig.
The first example is the evaluation of a line integral in the plane. We want to evaluate the integral of \(\mathbf{F(r)}=[-y, -xy]\) on the curve \(\mathbf{r(t)}=[-sin(t), cos(t)]\) from t=0 to t = π/2. The answer in the book is given as 0.4521. Here we evaluate this numerically, using autograd for the relevant derivative. Since the curve has multiple outputs, we have to use the jacobian function to get the derivatives. After that, it is a simple bit of matrix multiplication, and a call to the quad function.
import autograd.numpy as np
from autograd import jacobian
from scipy.integrate import quad
def F(X):
x, y = X
return -y, -x * y
def r(t):
return np.array([-np.sin(t), np.cos(t)])
drdt = jacobian(r)
def integrand(t):
return F(r(t)) @ drdt(t)
I, e = quad(integrand, 0.0, np.pi / 2)
print(f"The integral is {I:1.4f}.")
The integral is 0.4521.
# Checking what our output shapes look like
F([1, 1]), r(0), drdt(0.0)
((-1, -1), array([-0., 1.]), array([-1., -0.]))
t = np.linspace(0, np.pi / 2)
import matplotlib.pyplot as plt
plt.plot(t, [integrand(_t) for _t in t])
np.trapz([integrand(_t) for _t in t], t) # Just a numerical confirmation of our answer
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[3], line 5
1 t = np.linspace(0, np.pi / 2)
2 import matplotlib.pyplot as plt
3
4 plt.plot(t, [integrand(_t) for _t in t])
----> 5 np.trapz([integrand(_t) for _t in t], t) # Just a numerical confirmation of our answer
AttributeError: module 'autograd.numpy' has no attribute 'trapz'

We get the same result as the analytical solution.
Constrained optimization with Lagrange multipliers and autograd#
Constrained optimization is common in engineering problems solving. A prototypical example (from Greenberg, Advanced Engineering Mathematics, Ch 13.7) is to find the point on a plane that is closest to the origin. The plane is defined by the equation \(2x - y + z = 3\), and we seek to minimize \(x^2 + y^2 + z^2\) subject to the equality constraint defined by the plane. scipy.optimize.minimize provides a pretty convenient interface to solve a problem like this, as shown here.
import numpy as np
from scipy.optimize import minimize
def objective(X):
x, y, z = X
return x**2 + y**2 + z**2
def eq(X):
x, y, z = X
return 2 * x - y + z - 3
sol = minimize(objective, [1, -0.5, 0.5], constraints={"type": "eq", "fun": eq})
sol
message: Optimization terminated successfully
success: True
status: 0
fun: 1.5
x: [ 1.000e+00 -5.000e-01 5.000e-01]
nit: 1
jac: [ 2.000e+00 -1.000e+00 1.000e+00]
nfev: 4
njev: 1
multipliers: [ 1.000e+00]
I like the minimize function a lot, although I am not crazy for how the constraints are provided.
Sometimes, it might be desirable to go back to basics though, especially if you are unaware of the minimize function or perhaps suspect it is not working right and want an independent answer. Next we look at how to construct this constrained optimization problem using Lagrange multipliers. This converts the problem into an augmented unconstrained optimization problem we can use fsolve on. The gist of this method is we formulate a new problem:
\(F(X) = f(X) - \lambda g(X)\)
and then solve the simultaneous resulting equations:
\(F_x(X) = F_y(X) = F_z(X) = g(X) = 0\) where \(F_x\) is the derivative of \(F(X)\) with respect to \(x\), and \(g(X)\) is the equality constraint written so it is equal to zero. Since we end up with four equations that equal zero, we can simply use fsolve to get the solution. Many years ago I used a finite difference approximation to the derivatives. Today we use autograd to get the desired derivatives. Here it is.
import autograd.numpy as np
from autograd import grad
def F(L):
"Augmented Lagrange function"
x, y, z, _lambda = L
return objective([x, y, z]) - _lambda * eq([x, y, z])
# Gradients of the Lagrange function
dfdL = grad(F, 0)
F([0.0, 0.0, 0.0, 0.0]), dfdL([0.0, 0.0, 0.0, 0.0])
(0.0, [array(0.), array(0.), array(0.), array(3.)])
# Find L that returns all zeros in this function.
def obj(L):
x, y, z, _lambda = L
dFdx, dFdy, dFdz, dFdlam = dfdL(L)
return [dFdx, dFdy, dFdz, eq([x, y, z])]
from scipy.optimize import fsolve
x, y, z, _lam = fsolve(obj, [0.0, 0.0, 0.0, 1.0])
print(f"The answer is at {x, y, z}")
The answer is at (np.float64(1.0), np.float64(-0.5), np.float64(0.5))
dfdL([x, y, z, _lam]), _lam
([array(0.), array(0.), array(0.), array(0.)], np.float64(1.0))
That is the same answer as before. Note we have still relied on some black box solver inside of fsolve (instead of inside minimize), but it might be more clear what problem we are solving (e.g. finding zeros). It takes a bit more work to set this up, since we have to construct the augmented function, but autograd makes it pretty convenient to set up the final objective function we want to solve.
How do we know we are at a minimum? We can check that the Hessian is positive definite in the original function we wanted to minimize. You can see here the array is positive definite, e.g. all the eigenvalues are positive. autograd makes this easy too.
from autograd import hessian
h = hessian(objective, 0)
h(np.array([x, y, z]))
array([[2., 0., 0.],
[0., 2., 0.],
[0., 0., 2.]])
In case it isn’t evident from that structure that the eigenvalues are all positive, here we compute them:
np.linalg.eig(h(np.array([x, y, z])))[0]
array([2., 2., 2.])
Getting derivatives from implicit functions with autograd#
If we have an implicit function: \(f(x, y(x)) = 0\), but we want to compute the derivative \(dy/dx\) we can use the chain rule to derive:
\(df/dx + df/dy * dy/dx = 0\)
We can then solve for \(dy/dx\):
\(dy/dx = -df/dx / df/dy\)
to get the desired derivative. The interesting point of this is that we can get the two derivatives on the right hand side of this equation using automatic differentiation of the function \(f(x, y)\)! There are a few examples of analytical approaches to derivatives from implicit functions here we will use for example.
In the following examples, we will assume that \(y\) is a function of \(x\) and that \(x\) is independent. We will consider a series of implicit equations, compute \(dy/dx\) using autograd from the formula above, and compare them to the analytical results in the web page referenced above.
The \(dy/dx\) functions generally depend on both \(x\), and \(y\). Technically, these are the derivatives along the curve \(y(x)\), but since we can evaluate them at any points, we will use some random points for \(x\) and \(y\) to test for equality between the analytical derivatives and the autograd derivatives. This isn’t a rigorous proof of equality, but it is the only thing that makes sense to do for now. It is assumed that if these points are ok, all the others are too. That might be a broad claim, since we only sample \(x\) and \(y\) from 0 to 1 here but the approach is general. Here are the imports and the random test points for all the examples that follow.
import autograd.numpy as np
from autograd import grad
xr = np.random.random(50)
yr = np.random.random(50)
Next we consider \(x^3 + y^3 = 4\) as our implicit function.
\(df/dx = 3 x^2\)
\(df/dy = 3 y^2\)
so \(dy/dx = -x^2 / y^2\) for comparison.
def f1(x, y):
return x**3 + y**3 - 4
df1dx = grad(f1, 0)
df1dy = grad(f1, 1)
def dydx(x, y):
return -df1dx(x, y) / df1dy(x, y)
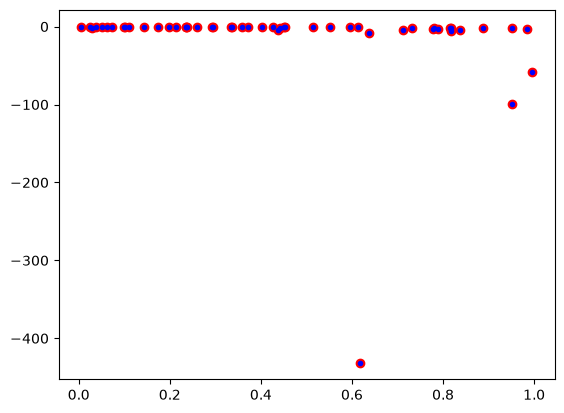
print(np.allclose(-(xr**2) / yr**2, [dydx(_xr, _yr) for _xr, _yr in zip(xr, yr)]))
plt.plot(xr, -(xr**2) / yr**2, "ro")
plt.plot(xr, [dydx(_xr, _yr) for _xr, _yr in zip(xr, yr)], "b.");
True
def f_1(X):
x, y = X
return x**3 + y**3 - 4
j = jacobian(f_1)
j(np.array([1.0, 1.0])), dydx(1.0, 1.0)
(array([3., 3.]), np.float64(-1.0))
The output of True means the autograd results and the analytical results are “all close”, i.e. within a tolerance the results are the same. The required derivatives of this are not that difficult to derive, but it is nice to see a simple example that “just works”. A subtle point of the dydx function is that it is not vectorized which is why I used a list comprehension to evaluate all the points. It is possible a pseudo-vectorized version with the np.vectorize decorator as shown here.
@np.vectorize
def dydx(x, y):
return -df1dx(x, y) / df1dy(x, y)
np.allclose(-(xr**2) / yr**2, dydx(xr, yr))
True
Scientific applications#
Compressibility variation from an implicit equation of state#
There are two ways to explore how some property varies with some parameter. One is if you have an equation relating them, you simply solve it many times for each parameter. Another is if you can derive an equation for how the property changes with parameter changes, then you have an ODE you can integrate. We explore that here. We will use the van der Waal equation of state to derive an equation for how the compressibility changes with the reduced pressure.
The general strategy to compute the compressibility as a function of pressure is to integrate \(dV / dP_r\) over a range of \(P_r\) to get the molar volume as a function of \(P_r\), and then to directly compute the compressibility from \(Z = PV/(RT)\).
To use this approach we need to get \(dV / dP_r\) from the van der Waal equation. Here, we follow the work in the previous section to get the derivative from the implicit form of the van der Waal equation:
\(f(V, P_r, T_r) = \frac{R Tr * Tc}{V - b} - \frac{a}{V^2} - P_r Pc = 0\)
We can get
\(dV/dP_r = (-df/dP_r) / (df/dV)\)
and the two derivatives on the right can be found easily by automatic differentiation. First, we express the van der Waal equation in implicit form, with the variables as \(V, P_r, T_r\). Only two of those variables are independent; if you define two of them you can compute the third one using a tool like fsolve.
R = 0.08206
Pc = 72.9
Tc = 304.2
a = 27 * R**2 * Tc**2 / (Pc * 64)
b = R * Tc / (8 * Pc)
Tr = 1.1 # Constant for this example
def f(V, Pr, Tr):
return R * Tr * Tc / (V - b) - a / V**2 - Pr * Pc
Now, if we want to know how does the volume vary with \(P_r\), we need to derive the derivative \(dV/dP_r\), and then integrate it. Here we use autograd to define the derivatives, and then we define a function that uses them. Note the arguments in the function dVdPr are in an order that anticipates we want to integrate it in solve_ivp, to get a function \(V(P_r)\).
from autograd import grad
dfdPr = grad(f, 1) # derivative of f with respect to arg at index=1: Pr
dfdV = grad(f, 0) # derivative of f with respect to arg at index=0: V
def dVdPr(Pr, V):
return -dfdPr(V, Pr, Tr) / dfdV(V, Pr, Tr) # Tr is a constant in here
Now, we need an initial condition to start the integration from. We want the volume at \(P_r=0.1\). We have to use fsolve for this, or some other method that tells you want is the volume at \(P_r=0.1\). We can pass the values of \(P_r\) and \(T_R\) as arguments to our implicit function. Since \(V\) is the first argument, we can directly solve our implicit function. Otherwise you would have to define a helper objective function to use with fsolve.
from scipy.optimize import fsolve
# Pr, V
(V0,) = fsolve(f, 3.5, args=(0.1, 1.1))
V0
np.float64(3.6764763125625435)
Finally, we are ready to integrate the ODE, and plot the solution.
import numpy as np
from scipy.integrate import solve_ivp
Pr_span = (0.1, 10)
Pr_eval, h = np.linspace(*Pr_span, retstep=True)
sol = solve_ivp(dVdPr, Pr_span, (V0,), max_step=h)
print(sol.message)
import matplotlib.pyplot as plt
Pr = sol.t # the P_r steps used in the solution
V = sol.y[0] # V(P_r) from the solution
Z = Pr * Pc * V / (R * Tr * Tc) # Compressibility Z(P_r)
plt.plot(Pr, Z)
plt.xlabel("$P_r$")
plt.ylabel("Z")
plt.xlim([0, 10])
plt.ylim([0, 2]);
The solver successfully reached the end of the integration interval.

There are several advantages of doing this over iteratively solving with fsolve. The biggest one is no initial guesses! It is also faster. What do you think would happen if there were multiple roots in the equation?
Computing the pressure from a solid equation of state#
A solid equation of state describes the energy of a solid under isotropic strain. We can readily compute the pressure at a particular volume from the equation:
\(P = -\frac{dE}{dV}\)
We just need the derivative of this equation:
\(E = E_0+\frac{B_0 V}{B'_0}\left[\frac{(V_0/V)^{B'_0}}{B'_0-1}+1\right]-\frac{V_0 B_0}{B'_0-1}\)
We use autograd to get it for us.
E0, B0, BP, V0 = -56.466, 0.49, 4.753, 16.573
def Murnaghan(vol):
E = E0 + B0 * vol / BP * (((V0 / vol) ** BP) / (BP - 1.0) + 1.0) - V0 * B0 / (BP - 1.0)
return E
def P(vol):
dEdV = grad(Murnaghan)
return -dEdV(vol) * 160.21773 # in Gpa
print(P(V0)) # Pressure at the minimum in energy is zero
print(P(0.99 * V0)) # Compressed
4.446935319979417e-15
0.8081676846907757
So it takes positive pressure to compress the system, as expected, and at the minimum the pressure is equal to zero. Seems pretty clear autograd is better than deriving the required pressure derivative.
Sensitivity analysis using automatic differentiation in Python#
This paper describes how sensitivity analysis requires access to the derivatives of a function. Say, for example we have a function describing the time evolution of the concentration of species A:
\([A] = \frac{[A]_0}{k_1 + k_{-1}} (k_1 e^{(-(k_1 + k_{-1})t)} + k_{-1})\)
The local sensitivity of the concentration of A to the parameters \(k1\) and \(k_1\) are defined as \(\frac{\partial A}{\partial k1}\) and \(\frac{\partial A}{\partial k_1}\). Our goal is to plot the sensitivity as a function of time. We could derive those derivatives, but we will use auto-differentiation instead through the autograd package.
import autograd.numpy as np
A0 = 1.0
def A(t, k1, k_1):
return A0 / (k1 + k_1) * (k1 * np.exp(-(k1 + k_1) * t) + k_1)
import matplotlib.pyplot as plt
t = np.linspace(0, 0.5)
k1 = 3.0
k_1 = 3.0
plt.plot(t, A(t, k1, k_1))
plt.xlim([0, 0.5])
plt.ylim([0, 1])
plt.xlabel("t")
plt.ylabel("A");

The figure above reproduces Fig. 1 from the paper referenced above. Next, we use autograd to get the derivatives. We need the derivative of the function with respect to the second and third arguments; the default is the first argument. Second, we want to evaluate this derivative at each time value. Finally, to reproduce Figure 2a, we plot the absolute value of the sensitivities.
from autograd import grad
fdAdk1 = grad(A, 1)
fdAdk_1 = grad(A, 2)
# grad is not vectorized so we evaluate it for each t
dAdk1 = [fdAdk1(_t, k1, k_1) for _t in t]
dAdk_1 = [fdAdk_1(_t, k1, k_1) for _t in t]
plt.plot(t, np.abs(dAdk1))
plt.plot(t, np.abs(dAdk_1))
plt.xlim([0, 0.5])
plt.ylim([0, 0.1])
plt.xlabel("t")
plt.legend(["$S_{k1}$", "$S_{k\_1}$"]);
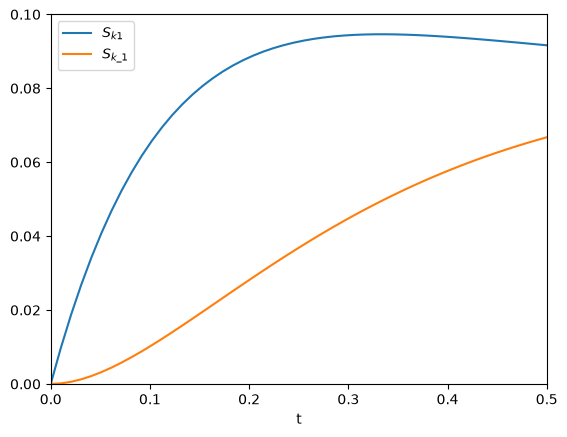
That looks like the figure in the paper. To summarize the main takeaway, autograd enabled us to readily compute derivatives without having to derive them manually.
Summary#
These are just some of many possible applications of automatic differentiation in mathematics and engineering. The key points you should take away from this is that it is often possible to program with derivatives, and to compute derivatives automatically in many cases. This enables you to think about writing programs that reflect the mathematical and scientific ideas you are trying to implement more directly, and in many cases less approximately.