Getting derivatives from implicit functions with autograd
Posted October 08, 2018 at 07:53 PM | categories: autograd, python | tags:
Table of Contents
If we have an implicit function: \(f(x, y(x)) = 0\), but we want to compute the derivative \(dy/dx\) we can use the chain rule to derive:
\(df/dx + df/dy dy/dx = 0\)
We can then solve for \(dy/dx\):
\(dy/dx = -df/dx / df/dy\) to get the desired derivative. The interesting point of this blog post is that we can get the two derivatives on the right hand side of this equation using automatic differentiation of the function \(f(x, y)\)! There are a few examples of analytical approaches to derivatives from implicit functions here, and I wanted to explore them with autograd in this post.
In the following examples, we will assume that \(y\) is a function of \(x\) and that \(x\) is independent. We will consider a series of implicit equations, compute \(dy/dx\) using autograd from the formula above, and compare them to the analytical results in the web page referenced above.
The \(dy/dx\) functions generally depend on both \(x\), and \(y\). Technically, these are the derivatives along the curve \(y(x)\), but since we can evaluate them at any points, we will use some random points for \(x\) and \(y\) to test for equality between the analytical derivatives and the autograd derivatives. This isn't a rigorous proof of equality, but it is the only thing that makes sense to do for now. It is assumed that if these points are ok, all the others are too. That might be a broad claim, since we only sample \(x\) and \(y\) from 0 to 1 here but the approach is general. Here are the imports and the random test points for all the examples that follow.
import autograd.numpy as np from autograd import grad xr = np.random.random(50) yr = np.random.random(50)
1 Example 1
\(x^3 + y^3 = 4\)
def f1(x, y): return x**3 + y**3 - 4 D1x = grad(f1, 0) D1y = grad(f1, 1) dydx_1 = lambda x, y: -D1x(x, y) / D1y(x, y) dydx_1a = lambda x, y: -x**2 / y**2 np.allclose(dydx_1a(xr, yr), [dydx_1(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
The output of True means the autograd results and the analytical results are "all close", i.e. within a tolerance the results are the same. The required derivatives of this are not that difficult to derive, but it is nice to see a simple example that "just works". A subtle point of the dydx function is that it is not vectorized which is why I used a list comprehension to evaluate all the points. It might be possible to make a pseudo-vectorized version with the np.vectorize decorator, but that is not of interest here.
2 Example 2
\((x - y)^2 = x + y - 1\)
def f2(x, y): return (x - y)**2 - x - y + 1 D2x = grad(f2, 0) D2y = grad(f2, 1) dydx_2 = lambda x, y: -D2x(x, y) / D2y(x, y) dydx2_a = lambda x, y: (2 * y - 2 * x + 1) / (2 * y - 2 * x - 1) np.allclose(dydx2_a(xr, yr), [dydx_2(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
This also works.
3 Example 3
\(y = sin(3x + 4y)\)
def f3(x, y): return y - np.sin(3 * x + 4 * y) D3x = grad(f3, 0) D3y = grad(f3, 1) dydx_3 = lambda x, y: -D3x(x, y) / D3y(x, y) dydx3_a = lambda x, y: (3 * np.cos(3 * x + 4 * y)) / (1 - 4 * np.cos(3 * x + 4 * y)) np.allclose(dydx3_a(xr, yr), [dydx_3(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
Check.
4 Example 4
\(y = x^2 y^3 + x^3 y^2\)
def f4(x, y): return y - x**2 * y**3 - x**3 * y**2 D4x = grad(f4, 0) D4y = grad(f4, 1) dydx_4 = lambda x, y: -D4x(x, y) / D4y(x, y) dydx4_a = lambda x, y: (2 * x * y**3 + 3 * x**2 * y**2) / (1 - 3 * x**2 * y**2 - 2 * x**3 * y) np.allclose(dydx4_a(xr, yr), [dydx_4(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
5 Example 5
\(e^{xy} = e^{4x} - e^{5y}\)
def f5(x, y): return np.exp(4 * x) - np.exp(5 * y) - np.exp(x * y) D5x = grad(f5, 0) D5y = grad(f5, 1) dydx_5 = lambda x, y: -D5x(x, y) / D5y(x, y) dydx5_a = lambda x, y: (4 * np.exp(4 * x) - y * np.exp(x * y)) / (x * np.exp(x * y) + 5 * np.exp(5 * y)) np.allclose(dydx5_a(xr, yr), [dydx_5(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
Also check.
6 Example 6
\(\cos^2 x + cos^2 y = cos(2x + 2y)\)
def f6(x, y): return np.cos(x)**2 + np.cos(y)**2 - np.cos(2 * x + 2 * y) D6x = grad(f6, 0) D6y = grad(f6, 1) dydx_6 = lambda x, y: -D6x(x, y) / D6y(x, y) dydx6_a = lambda x, y: (np.cos(x) * np.sin(x) - np.sin(2 * x + 2 * y)) / (np.sin(2 * x + 2 * y) - np.cos(y) * np.sin(y)) np.allclose(dydx6_a(xr, yr), [dydx_6(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
Check.
7 Example 7
\(x = 3 + \sqrt{x^2 + y^2}\)
def f7(x, y): return 3 + np.sqrt(x**2 + y**2) - x D7x = grad(f7, 0) D7y = grad(f7, 1) dydx_7 = lambda x, y: -D7x(x, y) / D7y(x, y) dydx7_a = lambda x, y: (np.sqrt(x**2 + y**2) - x) / y np.allclose(dydx7_a(xr, yr), [dydx_7(_xr, _yr) for _xr, _yr in zip(xr, yr)])
True
8 Conclusions
There are a handful of other examples at the website referenced in the beginning, but I am stopping here. After seven examples of quantitative agreement between the easy to derive autograd derivatives, and the easy to moderately difficult analytical derivatives, it seems like it is autograd for the win here. This technique has some important implications for engineering calculations that I will explore in a future post. Until then, this is yet another interesting thing we can do with automatic differentiation!
Copyright (C) 2018 by John Kitchin. See the License for information about copying.
Org-mode version = 9.1.13
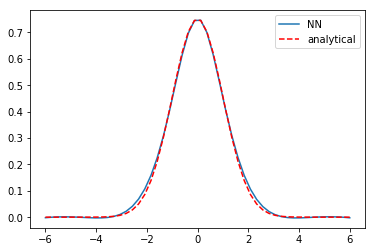
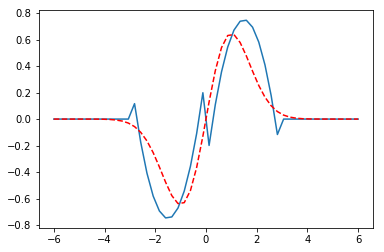
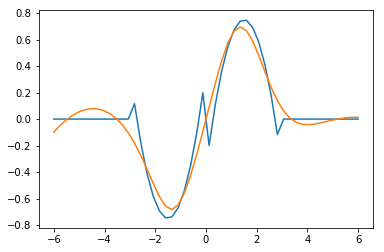
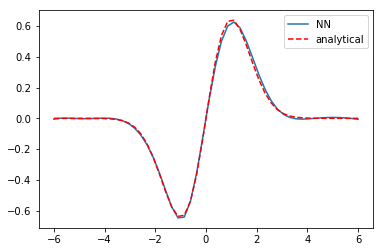
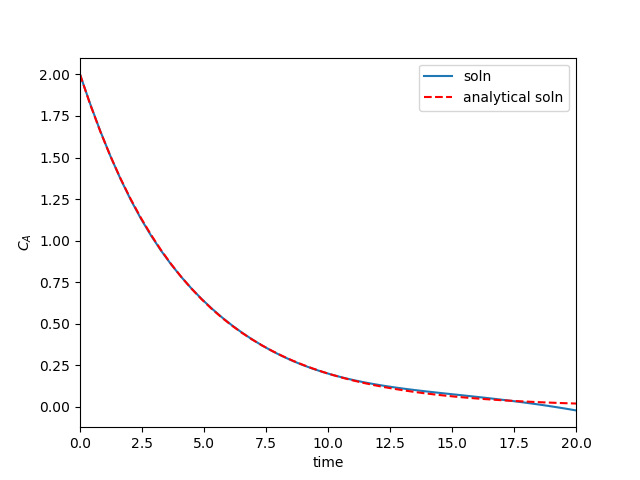
 I think it is worth discussing what we accomplished here. You can see we have arrived at an approximate solution to our differential equation and the boundary conditions. The boundary conditions seem pretty closely met, and the figure is approximately the same as the previous post. Even better, our solution is an actual function and not a numeric solution that has to be interpolated. We can evaluate it any where we want, including its derivatives!
I think it is worth discussing what we accomplished here. You can see we have arrived at an approximate solution to our differential equation and the boundary conditions. The boundary conditions seem pretty closely met, and the figure is approximately the same as the previous post. Even better, our solution is an actual function and not a numeric solution that has to be interpolated. We can evaluate it any where we want, including its derivatives!