A new ode integrator function in scipy
Posted September 04, 2018 at 09:20 PM | categories: scipy, ode | tags:
I learned recently about a new way to solve ODEs in scipy: scipy.integrate.solve_ivp. This new function is recommended instead of scipy.integrate.odeint for new code. This function caught my eye because it added functionality that was previously missing, and that I had written into my pycse package. That functionality is events.
To explore how to use this new function, I will recreate an old blog post where I used events to count the number of roots in a function. Spoiler alert: it may not be ready for production.
The question at hand is how many roots are there in \(f(x) = x^3 + 6x^2 - 4x - 24\), and what are they. Now, I know there are three roots and that you can use np.roots for this, but that
only works for polynomials. Here they are, so we know what we are looking for.
import numpy as np np.roots([1, 6, -4, -24])
array([-6., 2., -2.])
The point of this is to find a more general way to count roots in an interval. We do it by integrating the derivative of the function, and using an event function to count when the function is equal to zero. First, we define the derivative:
\(f'(x) = 3x^2 + 12x - 4\), and the value of our original function at some value that is the beginning of the range we want to consider, say \(f(-8) = -120\). Now, we have an ordinary differential equation that can be integrated. Our event function is simply, it is just the function value \(y\). In the next block, I include an optional t_eval arg so we can see the solution at more points.
def fprime(x, y): return 3 * x**2 + 12 * x - 4 def event(x, y): return y import numpy as np from scipy.integrate import solve_ivp sol = solve_ivp(fprime, (-8, 4), np.array([-120]), t_eval=np.linspace(-8, 4, 10), events=[event]) sol
message: 'The solver successfully reached the interval end.'
nfev: 26
njev: 0
nlu: 0
sol: None
status: 0
success: True
t: array([-8. , -6.66666667, -5.33333333, -4. , -2.66666667,
-1.33333333, 0. , 1.33333333, 2.66666667, 4. ])
t_events: [array([-6.])]
y: array([[-120. , -26.96296296, 16.2962963 , 24. ,
10.37037037, -10.37037037, -24. , -16.2962963 ,
26.96296296, 120. ]])
sol.t_events
[array([-6.])]
Huh. That is not what I expected. There should be three values in sol.t_events, but there is only one. Looking at sol.y, you can see there are three sign changes, which means three zeros. The graph here confirms that.
%matplotlib inline import matplotlib.pyplot as plt plt.plot(sol.t, sol.y[0])
[<matplotlib.lines.Line2D at 0x151281d860>]
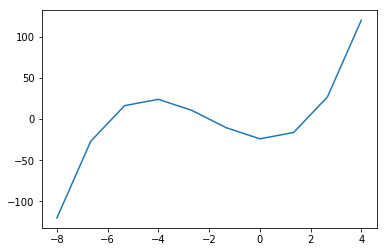
What appears to be happening is that the events are only called during the solver steps, which are different than the t_eval steps. It appears a workaround is to specify a max_step that can be taken by the solver to force the event functions to be evaluated more often. Adding this seems to create a new cryptic warning.
sol = solve_ivp(fprime, (-8, 4), np.array([-120]), events=[event], max_step=1.0)
sol
/Users/jkitchin/anaconda/lib/python3.6/site-packages/scipy/integrate/_ivp/rk.py:145: RuntimeWarning: divide by zero encountered in double_scalars max(1, SAFETY * error_norm ** (-1 / (order + 1))))
message: 'The solver successfully reached the interval end.'
nfev: 80
njev: 0
nlu: 0
sol: None
status: 0
success: True
t: array([-8. , -7.89454203, -6.89454203, -5.89454203, -4.89454203,
-3.89454203, -2.89454203, -1.89454203, -0.89454203, 0.10545797,
1.10545797, 2.10545797, 3.10545797, 4. ])
t_events: [array([-6., -2., 2.])]
y: array([[-120. , -110.49687882, -38.94362768, 3.24237128,
22.06111806, 23.51261266, 13.59685508, -1.68615468,
-16.33641662, -24.35393074, -19.73869704, 3.50928448,
51.39001383, 120. ]])
sol.t_events
[array([-6., -2., 2.])]
That is more like it. Here, I happen to know the answers, so we are safe setting a max_step of 1.0, but that feels awkward and unreliable. You don't want this max_step to be too small, because it probably makes for more computations. On the other hand, it can't be too large either because you might miss roots. It seems there is room for improvement on this.
It also seems odd that the solve_ivp only returns the t_events, and not also the corresponding solution values. I guess in this case, we know the solution values are zero at t_events, but, supposing you instead were looking for a maximum value by getting a derivative that was equal to zero, you might end up getting stuck solving for it some how.
Let's consider this parabola with a maximum at \(x=2\), where \(y=2\):
x = np.linspace(0, 4)
plt.plot(x, 2 - (x - 2)**2)
[<matplotlib.lines.Line2D at 0x1512dad9e8>]
We can find the maximum like this.
def yprime(x, y): return -2 * (x - 2) def maxevent(x, y): return yprime(x, y) sol = solve_ivp(yprime, (0, 4), np.array([-2]), events=[maxevent]) sol
/Users/jkitchin/anaconda/lib/python3.6/site-packages/scipy/integrate/_ivp/rk.py:145: RuntimeWarning: divide by zero encountered in double_scalars max(1, SAFETY * error_norm ** (-1 / (order + 1))))
message: 'The solver successfully reached the interval end.'
nfev: 20
njev: 0
nlu: 0
sol: None
status: 0
success: True
t: array([ 0. , 0.08706376, 0.95770136, 4. ])
t_events: [array([ 2.])]
y: array([[-2. , -1.65932506, 0.91361355, -2. ]])
Clearly, we found the maximum at x=2, but now what? Re-solve the ODE and use t_eval with the t_events values? Use a fine t_eval array, and interpolate the solution? That doesn't seem smart. You could make the event terminal, so that it stops at the max, and then read off the last value, but this will not work if you want to count more than one maximum, for example.
maxevent.terminal = True solve_ivp(yprime, (0, 4), (-2,), events=[maxevent])
/Users/jkitchin/anaconda/lib/python3.6/site-packages/scipy/integrate/_ivp/rk.py:145: RuntimeWarning: divide by zero encountered in double_scalars max(1, SAFETY * error_norm ** (-1 / (order + 1))))
message: 'A termination event occurred.'
nfev: 20
njev: 0
nlu: 0
sol: None
status: 1
success: True
t: array([ 0. , 0.08706376, 0.95770136, 2. ])
t_events: [array([ 2.])]
y: array([[-2. , -1.65932506, 0.91361355, 2. ]])
Internet: am I missing something obvious here?
Copyright (C) 2018 by John Kitchin. See the License for information about copying.
Org-mode version = 9.1.13