Indexing text in screenshots so they are searchable
Posted July 24, 2015 at 07:43 AM | categories: search, image | tags:
I had an interesting conversation with someone yesterday about using screenshots to document a process. This has an appeal of simplicity, since it is agnostic to the process, but I wondered about the long-term utility. If the documentation is valuable, you would like to search it in the future, and we so far have limited capability to search images. But, if there is important text in the image, we might be able to recognize the text, and use it to index the images. Then they would become searchable at least for the text in the image. Don't get me wrong, it would be better if we could store that text directly, but suppose that just isn't possible, maybe because it is all stored in some kind of gui, or it is locked up in proprietary software. Here we explore the potential utility of this. We only explore getting text out of images here, not the actual indexing part. See this post for how we could integrate this into an actual index and search tool.
First we need an OCR engine. Tesseract (tesseract-ocr/tesseract) is supposed to be pretty good, and it easily installs via brew:
brew install tesseract
(shell-command-to-string "tesseract -v")
tesseract 3.02.02 leptonica-1.72 libjpeg 8d : libpng 1.6.17 : libtiff 4.0.3 : zlib 1.2.5
We will test it on some screenshots taken with the default settings on my Mac. Here is an example. This example has text in color boxes, and some shadowing on the left side because another window was near it and that is some OS effect.
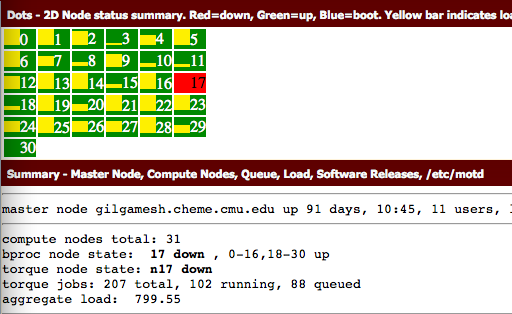
And here is the simplest text extraction.
tesseract ./screenshots/date-23-07-2015-time-19-56-52.png test cat test.txt rm test.txt
M. ~ an an. -.2... nuIunIrv- I.nd=d¢wn, a.....=.-p. u|u.=u_x. van" bar imam- smm-ry ~ nu... ma, Camilla man Qu-In lui. Sdlwnu u._-. /-x/mu master node q)l9amesh.chemc.cmn.edn up 9: days, mas, n nsersv cutflmltc nude: men): :1 bpxoc node sum 17 dmln , o.1s,u.:n up cuxque node state: n17 dawn tuxqng jobs: 207 max, m2 nmmnq. as queued aggregate laud: 799.55
That is not too good. I am skeptical it would be useful for anything. This page suggests improvements can be made with image clean up, but that image is pretty clear to me. There is a little shadow on the left side, but otherwise it is very readable to me. Let us try doubling the size of the image. Maybe that will help. Imagemagick lets us resize the image pretty easily.
convert -resize 200% ./screenshots/date-23-07-2015-time-19-56-52.png ./screenshots/doubled.png tesseract ./screenshots/doubled.png test cat test.txt rm test.txt ./screenshots/doubled.png
- 2D Node status summary. Rnd=down, Groun=up, BIu¢=boot. Vdlow bur indium -- Summlry - Hnflnr Mods, Compuh Nodu, Quuue, Land, Sofiwan Ric:-as, /dzc/maul master node gilqnmesh.cheme.cmu.edu up 91 days, 10:45, 11 users, .' compute nodes total: 31 bproc node state: 17 down , 0-16,18-30 up torque node state: n17 down torque jobs: 207 total, 102 running, 88 queued aggregate load: 799.55
That is a very remarkable improvement! This looks very useful, and could even be used for indexing. Interestingly, the white text on colored backgrounds does not do as well. That could be important to remember in designing the GUI front end if you have any say in it. Let's try a few others.
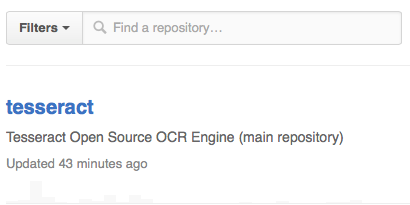
convert -resize 200% ./screenshots/date-23-07-2015-time-20-01-43.png ./screenshots/doubled.png tesseract ./screenshots/doubled.png test cat test.txt rm test.txt ./screenshots/doubled.png
Fllbn V Q I-"Ind a repository... tesseract Tesseract Open Source OCR Enghe (main repository) Updated 43 minutes ago
That is also pretty good. Again, the text on colored backgrounds is less good than that on a white background. And one more from Twitter.

convert -resize 200% ./screenshots/date-23-07-2015-time-20-05-59.png ./screenshots/doubled.png tesseract ./screenshots/doubled.png test cat test.txt rm test.txt ./screenshots/doubled.png
chEnected AIchE .-.ChEnected - 5h C h E AlChE Academy: Take AlChE‘s Pneumatic Conveying 0! Bulk Solids Course and learn practical design principles. r1m.ag/|IJcN
Overall pretty good. I am pretty convinced that the right screenshots could be an easy way to document some processes conveniently and that they could be searched in the future. Some testing would need to be done on how to do the OCR, and it does not appear that one recipe will work for all images.
Nevertheless, a program could pretty easily be developed to index a directory of screenshots, do the OCR on each image, and index the resulting text so it can be searched. It is even conceivable that several indexes could be made using different OCR methods that might work better for different types of images. Another improvement would be if some metadata could be associated with the screenshot including what instrument it is a shot of, who took it, etc… This starts to move in a direction that requires dedicated screenshot tools, and away from the simplicity of the PrintScreen button, but it adds value to the data that makes it easier to find later.
The beauty of the screenshot is that it is what you saw at the time, and it captures things as they were. It doesn't capture anything "behind the scenes" or off-screen of course, so there is certainly room to lose information this way. A careful analysis of what information is captured and what is lost would be important to assess the long-term value of capturing the process this way as opposed to any other way. There certainly is a balance of how much effort it takes to capture it and the value of the information in the future, and cost to rerun it if it isn't found in the future.
Copyright (C) 2015 by John Kitchin. See the License for information about copying.
Org-mode version = 8.2.10