Posted January 20, 2022 at 12:44 PM | categories:
publication, news | tags:
Updated January 20, 2022 at 12:44 PM
In this paper we combine density functional theory, machine learning, Monte Carlo simulations and experimental data to study segregation in a ternary alloy Cu-Pd-Au surface across the composition space. We found varying agreement and disagreement between tehe simulated and experimental results, and discuss the origins of these. Overall, Au segregates significantly across the composition space, and we learned a lot about the contributions to the discrepancies observed in Cu-Pd segregation and Au-Cu segregration.
@article{yang-2022-simul-segreg,
author = {Yilin Yang and Zhitao Guo and Andrew J. Gellman and John R.
Kitchin},
title = {Simulating Segregation in a Ternary Cu-Pd-Au Alloy With
Density Functional Theory, Machine Learning, and Monte Carlo
Simulations},
journal = {The Journal of Physical Chemistry C},
volume = {nil},
number = {nil},
pages = {acs.jpcc.1c09647},
year = 2022,
doi = {10.1021/acs.jpcc.1c09647},
url = {http://dx.doi.org/10.1021/acs.jpcc.1c09647},
DATE_ADDED = {Thu Jan 20 12:39:49 2022},
}
Copyright (C) 2022 by John Kitchin. See the License for information about copying.
Posted January 11, 2022 at 05:17 PM | categories:
news | tags:
Updated January 11, 2022 at 05:21 PM
I am excited to launch a new project this year: https://pointbreezepubs.gumroad.com/. This venture exists to publish booklets to help people learn how to use Python in science and engineering. Why am I doing this? I think computing skills are as important as domain knowledge today. I have spent the last 25 years learning how to use computing in science and engineering, and I have been teaching other people how to do that for the past 15 years. In that time huge changes have occurred in both hardware and software, data science and machine learning have emerged and they are playing a role almost everywhere. It has never been more important for people to learn how to use computers than it is today.
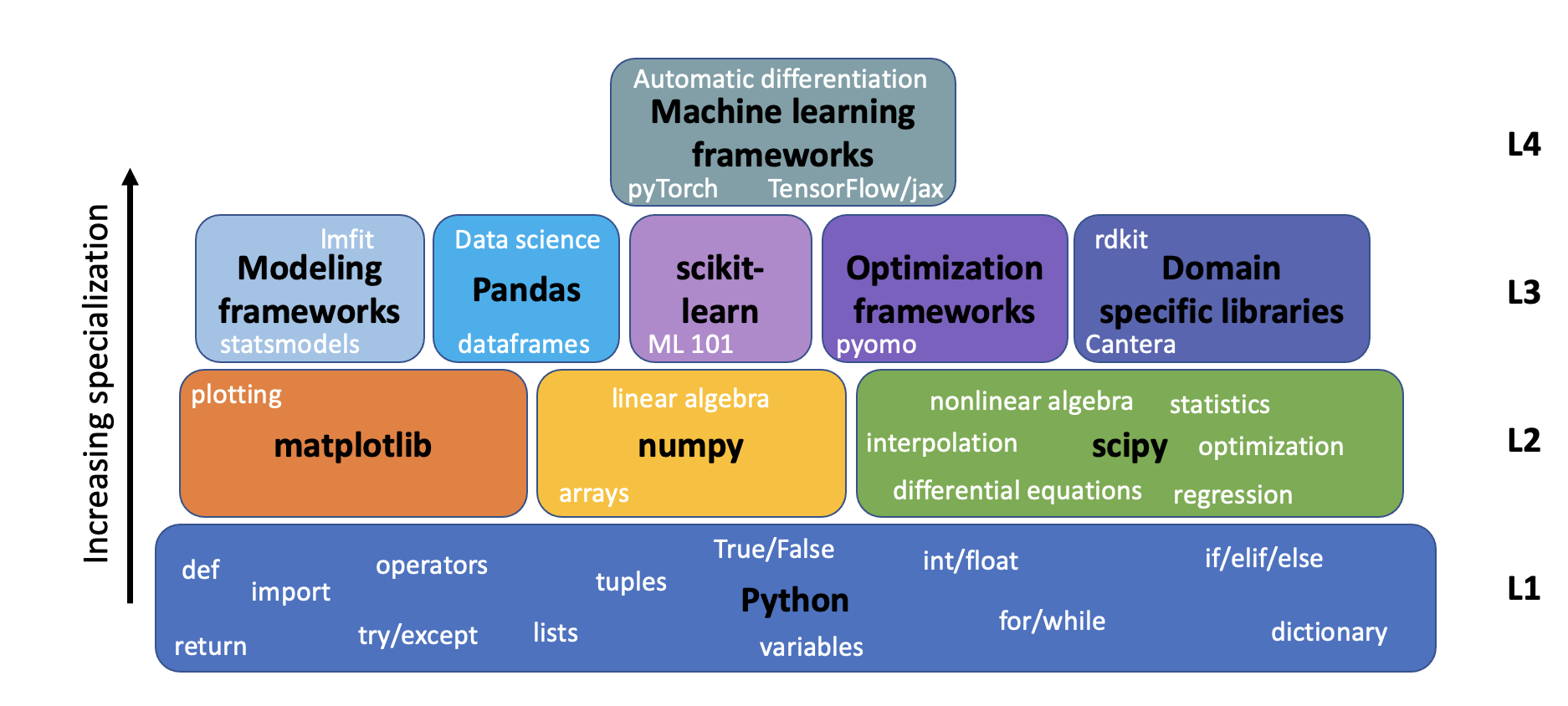
Solving science and engineering problems with computers requires first, and foremost, domain knowledge. Without that, you won't know what problem to solve, or know if the solution makes sense after you get it. It also requires complementary computational skills. Similar to a math education, where you first learn algebra, then geometry, and then calculus, you should not simply jump into data science or machine learning without a foundation of computational skills. I think of these skills like this:
Level 1 is basic programming in Python. Although everything rests on this foundation, this level alone does not solve many interesting problems in science and engineering. You have to combine this with some mathematical domain knowledge in level 2 to get to those. Levels 1 and 2 are adequate for many common science and engineering problems. If you move in a direction of specialization, especially using computers, it is often found that even though levels 1 and 2 are adequate, they may become tedious in large problems, or when used frequently. The solution is almost always to create an abstraction, a framework, that removes the tedium, and is more convenient to use. This is level 3. The abstraction hides a lot of detail, and can make it more difficulty to customize behavior, but the payoff is convenience. Finally, and this is debatable, I think level 4 contains today's machine learning frameworks. I separate them from level 3 because they are often used to write tools used in level 3, and they typically require skills that are not learned in level 2.
So how does Point Breeze Publishing help here? We have published the first step in this booklet:
These booklets come in two forms: PDF and ipynb. The first is traditional, and easy to read. The second format is less traditional, but it allows you to execute the code yourself to see how it works.
Over the next few weeks, I will publish these additional booklets, with some supplementary materials.
Intermediate Python computations in science and engineering
Python computations for lab courses
Ordinary differential equations
Optimization in Python
These booklets cover most of what chemical engineering undergraduate students need (my opinion of course), and lay a solid foundation for levels 3 and 4 as described above. These are not reference books, or documentation from the packages. They are a guided tour through the topics to help you get started, learn how to think about these topics, and become a self-learner in them.
Where to from here? Over the summer, I will work on some more advanced booklets on data science and machine learning. I will also explore some other ways to deliver these booklets. I use PDF and ipynb now because I know how to do it, but other options exist.
This whole venture is possible because of scimax, and I hope this becomes a route to publish books about using scimax for scientists and engineers.
I skipped the last two years of these it looks like. This year is ending in a better place than last year, so here is a nutshell for the past year!
1. Service accomplishments
This year I led an effort to create a Diversity, Equity and Inclusion committee within the Department of Chemical Engineering. I also serve on our college level DEI committee. It has been a challenging year to do this work mostly by Zoom, but I am proud of what our group has been able to do in the department and college. This isn't really new work, I have been involved in some way or another for six or seven years, but this past year was a major elevation of that work.
2. Research group accomplishments
Jenny (Ni) Zhan successfully defended her PhD and has graduated in 2021. Congratulations Jenny!
Two new MS students joined the group, Luyang Liu and Ananya Srivastava. They are starting a new research direction in natural language processing.
Omar Jimènez-Negrón finished his REU work with us, and has accepted a graduate position at Ga Tech.
3. Publications
This year was a better year than last year for publications. Our work this year covered a pretty broad range of topics from liquid metal alloys, to hydrogen production, to algorithms in uncertainty quantification and molecular simulation. My students and collaborators did a fantastic job on this work. Thank you!
Bhat, M., Lopato, E., Simon, Z. C., Millstone, J. E., Bernhard, S., & Kitchin, J. R. (2022). Accelerated optimization of pure metal and ligand compositions for light-driven hydrogen production. Reaction Chemistry & Engineering. http://dx.doi.org/10.1039/d1re00441g
Simon, Z. C., Lopato, E. M., Bhat, M., Moncure, P. J., Bernhard, S. M., Kitchin, J. R., Bernhard, S., Millstone, J. E. (2021). Ligand enhanced activity of in situ formed nanoparticles for photocatalytic hydrogen evolution. ChemCatChem, http://dx.doi.org/10.1002/cctc.202101551
Zhan, N., & Kitchin, J. R. (2021). Uncertainty quantification in machine learning and nonlinear least squares regression models. AIChE Journal, http://dx.doi.org/10.1002/aic.17516
Yang, Y., Omar A. Jimènez-Negrón, & Kitchin, J. R. (2021). Machine-learning accelerated geometry optimization in molecular simulation. The Journal of Chemical Physics, 154(23), 234704. http://dx.doi.org/10.1063/5.0049665
Liu, M., Yang, Y., & Kitchin, J. R. (2021). Semi-grand canonical Monte Carlo simulation of the acrolein induced surface segregation and aggregation of AgPd with machine learning surrogate models. The Journal of Chemical Physics, 154(13), 134701. http://dx.doi.org/10.1063/5.0046440
4. org-ref version 3
I wrote and released org-ref version 3. The new version provides much better support for pre and post notes, and uses CSL for non-LaTeX exports, which is should be a big improvement over version 2. org-ref has been downloaded from MELPA more than 180,000 times now! It is amazing this tool I wrote to make my life easier has had such an impact.
The citation space in org-mode is a little complicated now because org-mode now has its own citation syntax. I tried hard to find a way to use that in org-ref, but I was unable to find a way that would also support legacy org-ref documents, and that also supports the cross-references, indexes, glossary and acronym features of org-ref. org-ref remains focused on supporting these in scientific documents, and staying close to the way they would look in LaTeX.
5. YouTube
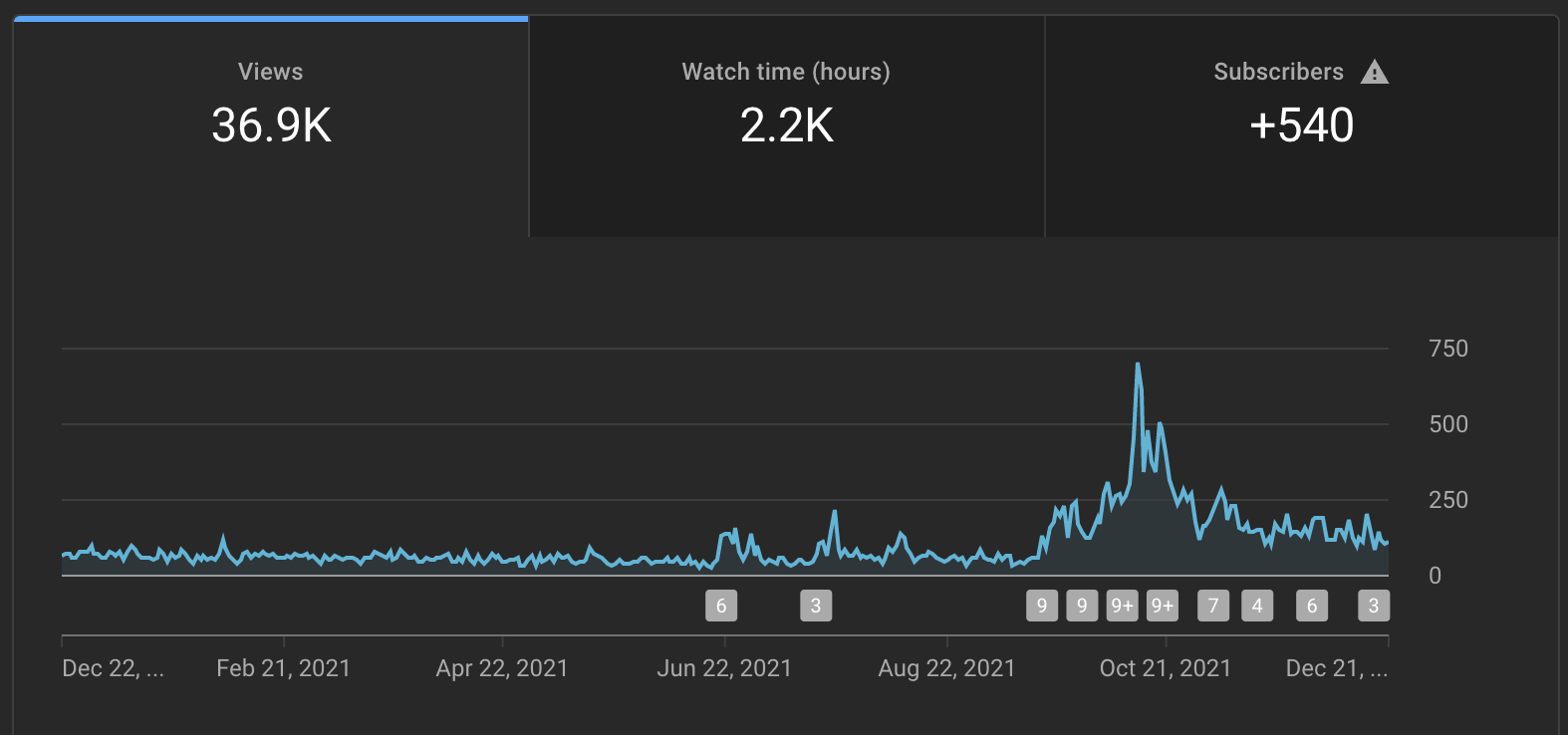
Back in September I started making YouTube videos again around the release of org-ref v3. I started a new pycse playlist about Python. Check it out and subscribe if you like it! I also started making video briefs on our research papers and some research talks as an experiment. You can see here it made a difference in the channel traffic. At 2200 hours of watch time, this is an interesting kind of outreach and public impact from our work.
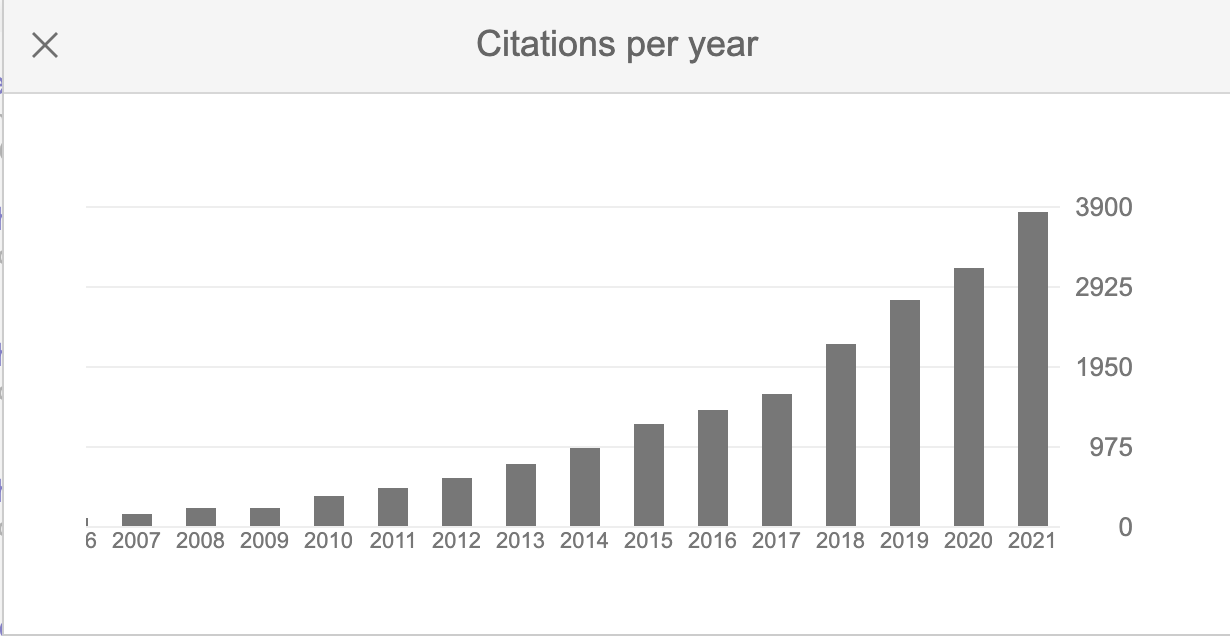
Why is this a good idea? Check out our publication page https://kitchingroup.cheme.cmu.edu/publications.html. You can see the Altmetric scores on our papers are generally pretty good, and even our newer papers are getting cited. It certainly has not hurt our citations per year according to Google Scholar.
It is also kind of fun.
6. Outlook for 2022
Things look ok for 2022. Probably I will start traveling for work again, so I hope to see some of you in person soon! I will limit travel pretty strictly, and remain vigilant about masking, so don't plan on any meals or outings to bars just yet!
I am teaching my Data science in chemical engineering course again and a new software engineering course this Spring which should be fun! Finally, stay tuned, hopefully I will have some news on a new venture I am trying to get started early in 2022!
Copyright (C) 2021 by John Kitchin. See the License for information about copying.
Posted December 18, 2021 at 09:06 AM | categories:
publication, news | tags:
In many liquid metal alloys the diffusivity and viscosity are related to each other through the Stokes–Einstein–Sutherland (SES) equation. This is useful because it is difficult to measure these properties in liquid metals, and the correlation can be used in design. Near the melting point, however, this relation often fails. In this work we use molecular dynamics to investigate deviations in the SES for molten Si-Al. We find that the viscosity changes faster than the diffusivity due to the formation of atomic clusters. These clusters cause the SES deviation in this liquid alloy system.
@article{zhan-2021-origin-stokes,
author = {Ni Zhan and John R. Kitchin},
title = {Origin of the Stokes-Einstein Deviation in Liquid Al-Si},
journal = {Molecular Simulation},
volume = {},
number = {},
pages = {1-11},
year = 2021,
doi = {10.1080/08927022.2021.2012572},
url = {http://dx.doi.org/10.1080/08927022.2021.2012572},
DATE_ADDED = {Fri Dec 17 07:41:39 2021},
}
Copyright (C) 2021 by John Kitchin. See the License for information about copying.
Posted December 03, 2021 at 09:20 AM | categories:
publication, news | tags:
In this new collaborative work we show how we combine a high-throughput photoreactor with a design of experiment approach to efficiently find optimal in situ synthesis compositions for making metal nanoparticle catalysts for light-driven hydrogen production. The challenge in this work is there are several components that interact with each other including metal salts, stabilizing ligands and photosensitizers, as well as some noise in the measurements. It is difficult to optimize these components one at a time, so we use a design of experiment approach. The high-throughput data enables us to explore the composition space around the optimum and to identify specific compositions for focused and expensive characterization efforts. We use this on Au, Cu, Fe and Ni and show that all of them can have high activity when they are independently optimized. It is interesting to note that Au and Cu form stable metallic nanoparticles, but Ni appears to form oxide nanoparticles and Fe appears to form sulfide nanoparticles.
@article{bhat-2022-accel-optim,
author = {Maya Bhat and Eric Lopato and Zoe C Simon and Jill E Millstone
and Stefan Bernhard and John R Kitchin},
title = {Accelerated Optimization of Pure Metal and Ligand Compositions
for Light-Driven Hydrogen Production},
journal = {Reaction Chemistry \& Engineering},
volume = {},
number = {},
pages = {},
year = 2022,
doi = {10.1039/d1re00441g},
url = {http://dx.doi.org/10.1039/D1RE00441G},
DATE_ADDED = {Mon Nov 29 17:00:12 2021},
}
Copyright (C) 2021 by John Kitchin. See the License for information about copying.